Team Members: @Anastasios Stamoulakatos and @Thanos Lyras
Bitbucket Repo: https://bitbucket.org/satalia/data_science_agent_adk/src/main/
Elevator pitch: An AI agent that continuously monitors your data to identify and report both structural and logical errors. The agent improves itself by remembering its past findings and calibrating its future monitoring efforts. It protects data quality at scale, reducing manual oversight while improving trust in the systems and decisions that depend on that data.
Data Quality Assurance Agent Technical Walkthrough
Introduction
Data quality assurance (QA) is a critical bottleneck in modern data engineering pipelines. Engineers frequently dedicate a disproportionate amount of time to manually profiling, verifying, and debugging datasets before they are cleared for downstream consumption by data scientists to build machine learning models. This manual intervention is unscalable, computationally inefficient, and prone to human error, particularly when validating complex, cross-column business logic within wide tables.
To address this infrastructure gap, we architected and deployed the Data Quality Assurance Agent. Operating directly against our Google BigQuery data warehouse, the agent can autonomously interpret schemas, execute targeted NL2SQL anomaly detection queries, and generate comprehensive diagnostic reports.
An important feature of this agent is its long-term memory architecture, hosted via Vertex AI Agent Engine. By indexing and retrieving historical context across sessions, the agent dynamically suppresses established baseline anomalies and adapts its detection heuristics based on previous human-in-the-loop corrections.
To validate the agent’s detection capabilities under controlled and reproducible conditions, we developed a synthetic data generation pipeline that injects known structural and logical anomalies at configurable rates into anonymized, marketing data. Evaluation was conducted across 3 experimental configurations, spanning three prompt complexity levels and two memory modes, with scoring fully automated via an LLM-as-a-Judge pipeline using Gemini as the evaluator. The agent achieved a peak detection rate of 0.883% across all injected error categories under forensic-level prompting.
Agent Architecture
The solution is structured around a hierarchical multi-agent orchestration pattern, with a central Root Agent coordinating seven specialized sub-agents, as illustrated in the diagram below. The Root Agent functions as an LLM-powered intent classifier: it parses each incoming user request, decomposes compound instructions into an ordered execution plan, and dynamically routes sub-tasks to the appropriate specialist agent, without relying on hard-coded conditional routing logic. This design enables the system to handle chained, multi-step requests (e.g., “query the database and then plot the results”) by composing multiple sub-agents in sequence within a single session. The architecture was inspired by ADK’s official examples repo.
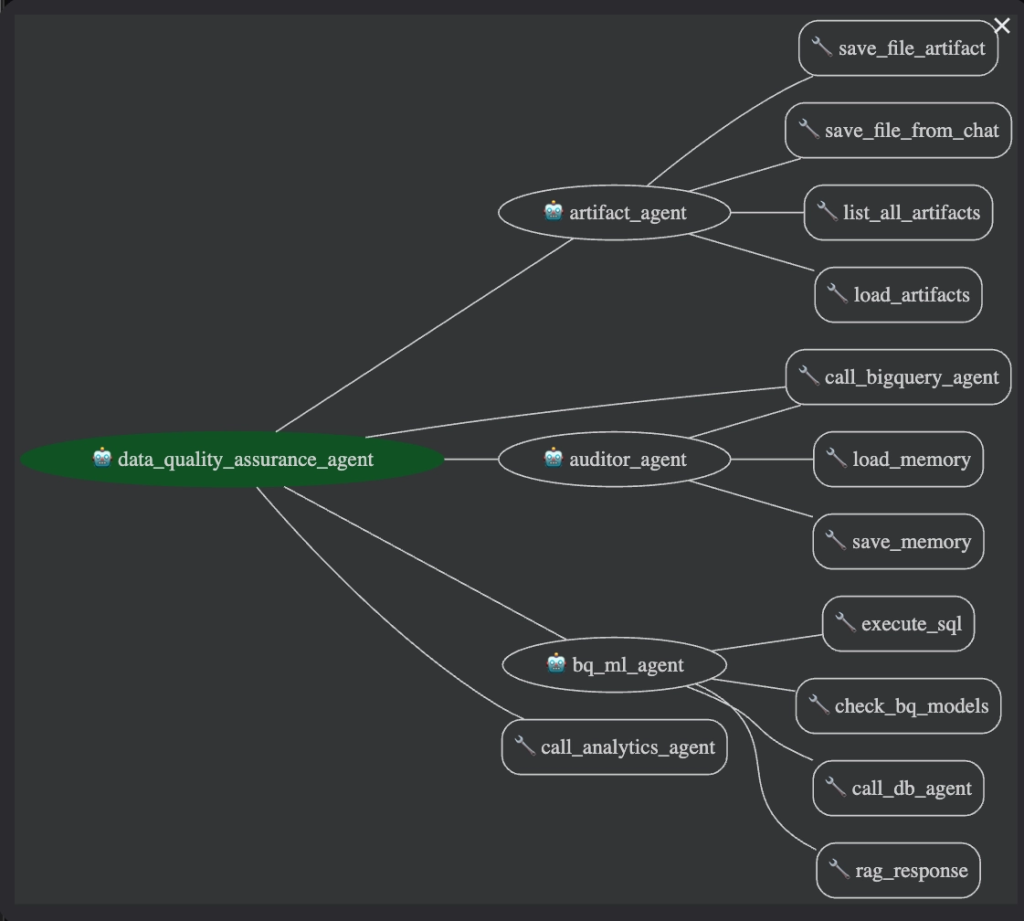
Sub-Agent Inventory
The system employs a multi-agent orchestration architecture where a primary Root Agent delegates tasks to specialized sub-agents based on user intent. All agents are powered by Gemini 2.5 Flash, optimized for complex multi-step reasoning, low inference latency, and cost efficiency under high request volume.
| Sub-Agent | Core Responsibility |
|---|---|
| Auditor Agent | Drives autonomous data quality auditing by executing structural and logical checks against BigQuery, maintaining historical context via the Memory Bank. |
| BigQuery Agent | Facilitates Text-to-SQL (NL2SQL) translation, generating optimized queries and executing them directly against the data warehouse. |
| Analytics Agent | Performs Advanced Data Analysis (NL2Py) by dynamically generating and executing Python code within a secure Vertex AI sandbox for statistical profiling and visualization. |
| BQML Agent | Orchestrates BigQuery ML workflows, including model training, batch inference, and model lifecycle management. |
| Artifact Agent | Handles session-scoped file management to save, retrieve, and list generated execution artifacts (images, CSVs, PDFs). |
| Report Agent* | Synthesizes audit findings into multi-format reports (Markdown, HTML, PDF, JSON) and manages artifact uploads to Google Cloud Storage. |
| Comparison Agent* | Executes schema-level and volume-level structural comparisons across discrete BigQuery tables. |
- Note: The Report and Comparison agents are fully implemented in the repository but are intentionally disconnected from the Root Agent’s execution chain in this evaluation instance.
Key System Capabilities
- Dynamic Intent Classification: The Root Agent accurately decomposes complex natural language requests, determines the optimal execution path, and dynamically invokes the correct sub-agent chain.
- NL2SQL Querying: The BigQuery Agent seamlessly translates natural language into optimized SQL, executing it directly against the data warehouse to extract and analyze data without friction.
- NL2Py Analysis: The Analytics Agent dynamically generates and executes Python code within a secure Vertex AI Code Interpreter sandbox, unlocking advanced statistical profiling, custom visualizations, and complex cross-dataset joins.
- Autonomous Data Auditing: The Auditor Agent runs a comprehensive suite of structural and logical validation checks against BigQuery datasets, producing structured, reproducible diagnostic reports.
- Stateful Memory Persistence: By querying a persistent Memory Bank, the Auditor contextualizes newly detected anomalies against historically resolved or suppressed issues, ensuring the agent learns and adapts from past executions.
- Multi-Format Report Compilation: The Report Agent synthesizes raw audit findings into polished, user-preferred output formats and automatically pushes the final artifacts to Google Cloud Storage for human review.
Long-Term Memory Bank
The system’s persistent Memory Bank, hosted on Vertex AI Agent Engine, gives the auditor institutional knowledge across sessions, eliminating cold-start noise and adapting its behaviour to individual user preferences over time. The Memory Bank tracks two custom semantic categories:
| Topic | Examples |
|---|---|
| Data Quality Issues | Missing columns, inflated metric values, recurring table-level anomalies |
| User Preferences | “Always include an executive summary”; “Flag outliers beyond 3σ” |
How Memory Is Saved
Memory persistence is user-directed. The Auditor invokes the save_memory tool only when explicitly asked (e.g., “…and save these findings to memory”). The Vertex AI Agent Engine then asynchronously extracts clean semantic facts from the session — stripping noise and verbose phrasing — and indexes them against the user’s user_id scope. When a new lesson or correction occurs, the agent doesn’t just blindly append a new memory; instead, it actively scans for similar existing entries. If a related memory is found, the system updates and refines the existing rule rather than creating a duplicate. This deduplication process ensures the knowledge base remains clean, concise, and highly effective, preventing the auditor from getting overwhelmed by redundant information over time.
Crucially, Agent Engine also persists the full conversation session alongside the extracted facts, meaning the complete interaction history — including tool calls, SQL queries, and agent reasoning — is retained across runs. This gives the system two complementary layers of recall: structured fact memory (distilled semantic facts) and full session continuity (complete conversation history), both managed within a single Vertex AI service.
How Memory Is Loaded
When a query includes a load instruction (e.g., “load memories then check table X”), the Auditor calls the ADK LoadMemoryTool, which runs a similarity search against the Memory Bank scoped to the current user_id. Retrieved facts are injected into the agent’s working context before analysis begins, enabling it to:
- Suppress re-flagging of known, already-resolved issues
- Apply user formatting preferences from the first response
- Re-verify previously detected anomalies to check if they persist
Technology Stack
| Component | Technology | Role |
|---|---|---|
| Agent Framework | Google Agent Development Kit (ADK) | Agent orchestration, tool binding, session management, and A2A protocol support |
| LLM (Agents) | Gemini 2.5 Flash | Powers all sub-agents; chosen for low latency and strong instruction-following |
| LLM (Judge) | Gemini 2.5 Flash | Powers the LLM-as-a-Judge evaluation pipeline; stronger reasoning for unbiased scoring |
| Data Warehouse | Google BigQuery | Primary data store; queried via NL2SQL by both the BigQuery and Auditor agents |
| Code Execution | Vertex AI Code Interpreter | Sandboxed Python runtime for the Analytics Agent |
| Long-Term Memory | Vertex AI Agent Engine | Hosts the persistent Memory Bank; enables cross-session learning and recall |
| Artifact Storage | Google Cloud Storage | Persistent store for generated reports, JSON profiles, and session artifacts |
| Deployment | Google Cloud Run | Hosts both the A2A API backend and the interactive web UI as containerized services |
| CI/CD | Bitbucket Pipelines | Automated build, Docker image push to Artifact Registry, and Cloud Run deployment on merge |
| Interoperability | A2A Protocol | Open HTTP-based standard enabling external agents and services to discover and invoke the system programmatically |
Dataset Synthesis
Evaluating an autonomous auditing agent requires a controlled, reproducible ground truth, something that real-world production data cannot provide, since errors are unverified by definition. To solve this, we engineered a modular synthetic corruption pipeline that operates on proprietary synthetic datasets designed to mirror real-world marketing dynamics, and produces deterministically corrupted BigQuery tables accompanied by a complete ground truth registry for automated scoring.
Source Dataset
To ensure robust and repeatable results, we start with proprietary synthetic datasets giving us complete control and clear visibility into the drivers of campaign performance. The source dataset is a digital marketing performance table comprising 7,618 rows and 87 feature columns. Each record represents a unique daily measurement at the intersection of a campaign, audience segment, delivery platform, ad placement, and creative asset. Columns are organized into six functional groups:
| Column Group | Description |
|---|---|
| Brand & Advertiser | Identity of the brand and advertiser running the campaign |
| Campaign & Media Buy | Campaign IDs, names, and media buying hierarchy |
| Geo Targeting | Geographic targeting and exclusion rules (countries, regions, cities) |
| Audience Targeting | Demographic segments: gender, age group, generation, interests, and behaviors |
| Delivery & Platform | Campaign objective, platform (Meta/Instagram), device type, and ad placement |
| Performance Metrics | Funnel KPIs: impressions, clicks, spend, conversions, video plays, video completions, landing page views, add-to-cart events, and purchases |
The Performance Metrics group is the most analytically significant: the columns encode a strict, real-world causal funnel (impressions → clicks → landing page views → add-to-cart → conversions/purchases) where each downstream metric is physically bounded by the upstream one. Violations of these relationships — where, for example, clicks > impressions — are logically impossible under normal operating conditions. This funnel structure forms the basis for all logical error injection. Additionally, the dual attribution windows (immediate vs. 7-day) introduce latent complexity: the complex prompt level successfully identified cross-window contradictions as an un-injected source of potential logical ambiguity.
Corruption Pipeline
The pipeline is structured as a three-stage process. Anonymization is performed first, followed by structural error injection, and concluding with logical error injection. These stages consist of composable modules that can be selectively enabled or combined to produce datasets with precisely controlled corruption profiles. The error rate is fully configurable per stage and can be held constant (for fixed-recall benchmarks) or varied progressively form 5 to 40% (to model the agent’s sensitivity as a function of corruption severity).
Stage 1 — Anonymization
As a preprocessing step, the pipeline replaces PII and commercially sensitive fields (brand, campaign, creative) with generic identifiers (e.g., brand_1, campaign_1), while cleanly preserving all structural relationships.
Stage 2 — Structural Errors
Structural anomalies target individual cells, columns, or rows, and are generally detectable through standard data profiling techniques. This stage consists of five independent injection modules:
| Error Type | Simulation / Injection Method |
|---|---|
| Missing Values (Nulls) | Injects NaN values across a configurable subset of columns to simulate missing or dropped data. |
| Outliers | Replaces numeric values with statistical extremes (mean ± k × std) to simulate sensor noise or ETL overflow. |
| Duplicate Rows | Duplicates randomly selected rows and re-inserts them at random positions to simulate pipeline idempotency failures. |
| Categorical Errors | Replaces valid categories with unique random alphanumeric strings (e.g., a3x7h9) guaranteed not to be in any valid vocabulary. |
| Schema Drift (Col Drops) | Randomly removes entire columns to simulate upstream data source failures. |
Stage 3 — Logical Errors
Logical errors are the hardest class of anomalies to detect. Every individual cell value is numerically valid; the violation only becomes apparent when two or more columns are evaluated relationally. This stage injects records that violate any of the following seven business rules:
| # | Rule Violated | Condition Injected |
|---|---|---|
| 1 | Clicks ≤ Impressions | clicks > impressions |
| 2 | Conversions ≤ Clicks | conversions > clicks |
| 3 | Spend requires Impressions | spend > 0 AND impressions = 0 |
| 4 | Video Completions ≤ Plays | video_completions > video_plays |
| 5 | Purchases require Add-to-Cart | purchases > 0 AND add_to_cart = 0 |
| 6 | Landing Page Views ≤ Clicks | landing_page_views > clicks |
| 7 | Non-negative Metric Values | Negative values injected into impressions, clicks, spend, or conversions |
Ground Truth Registry
The evaluation framework is anchored by our ground truth dataset, a structured registry of all 59 BigQuery test tables used in the experiment suite. Each row maps a table’s BigQuery name to its complete injection specification:
- the number of logical errors injected (out of a maximum of 7 possible rule types)
- the exact error type labels (e.g., clicks_exceed_impressions, purchases_without_add_to_cart)
- the number of structural errors injected (out of 4 possible types), and their corresponding labels (e.g., null values, outliers, duplicates, categorical errors)
The registry covers two tiers of test tables; 48 single-error tables (examples 1–48), each containing one isolated error type at varying injection rates of 5%, 10%, 20%, and 40%; and 11 compound synthetic tables (examples 49–59) with progressively stacked errors — starting from a single logical violation and escalating to the maximum combination of all 7 logical and all 4 structural error types simultaneously.
| Table Name | Logical Errors | Logical Error Types | Structural Errors | Structural Error Types |
|---|---|---|---|---|
..._categorical_error_5_percent | 0 | — | 1 / 4 | categorical errors |
..._logical_error_1_5_percent | 1 / 7 | clicks_exceed_impressions | 0 | — |
log_1_5_pt_log_2_5_pt_log_3_5_pt_..._dup_5_pt_cat_5_pt | 7 / 7 | clicks_exceed_impressions, conversions_exceed_clicks, landing_page_views_exceed_clicks, negative_metric_values, purchases_without_add_to_cart, spend_with_zero_impressions, video_completions_exceed_plays | 4 / 4 | null values, outliers, duplicates, categorical errors |
Evaluation Pipeline
Rigorous evaluation of the auditor agent is essential to ensure it consistently and accurately identifies true data corruption without generating false positives. To accomplish this, the evaluation pipeline uses an automated, four-step process to continuously assess the agent’s performance. First, the pipeline utilizes synthetic ground truth data stored in BigQuery tables, seeded with deliberate structural and logical errors (such as NULLs, duplicates, and business-rule violations). Second, the auditor agent is executed against these tables through multiple experimental setups, including prompt comparisons (simple vs. complex queries), table anomaly sweeps, and memory ablation studies (cold starts vs. loading past audits). During these runs, the agent uses its SQL tools to investigate the data and generates a comprehensive final audit report.
Third, rather than relying on slow manual review, we automate the evaluation using an LLM-as-a-Judge approach. A separate Gemini Flash instance receives the agent’s full audit report alongside the complete ground truth registry. Acting as an expert evaluator, the judge compares the outputs and produces a structured scorecard with ✅/❌ verdicts and brief explanations for every error category. This eliminates subjective scoring bias and allows new prompt designs or memory configurations to be evaluated end-to-end in minutes. Finally, these scorecards are parsed to compute precision, recall, and F1 scores per error type, which are then exported to CSV for detailed analysis.
This is also illustrated in the diagram below:

Experimental Setup
To rigorously validate the Auditor agent’s detection capabilities, we designed a suite of three complementary experiments, each isolating a different factor that influences audit performance:
- Experiment 1 — Prompt Comparison: Measures how the complexity and specificity of the user prompt affects the agent’s ability to detect both structural and logical errors, comparing a simple exploratory prompt against a medium-structured prompt and a forensic-level complex prompt.
- Experiment 2 — Table Sweep: Stress-tests the agent’s scalability and robustness by sweeping across 11 synthetic tables with progressively stacked error combinations — from a single isolated violation up to the maximum of 11 simultaneous error types — to map the detection ceiling under the best-performing prompt.
- Experiment 3 — Memory Ablation: Isolates the contribution of the long-term Memory Bank by comparing a cold-start baseline (no prior context) against a memory-augmented run, quantifying how historical context from past audit sessions improves detection accuracy.
Together, these experiments span the key dimensions of agent performance — prompt engineering, error complexity, and contextual memory — providing a comprehensive view of the system’s strengths and current limitations. All experiments use the same synthetic corruption pipeline and LLM-as-a-Judge scoring framework described above.
Experiment 1: Prompt Comparison
Our first research question was whether prompt specification (instructional structure, domain constraints, and required check set) is a first-order driver of audit performance, independent of the underlying dataset and injected corruption profile. In other words, does increasing prompt information content and enforcing explicit cross-column invariants improve the agent’s ability to surface structural anomalies and relational business-rule violations, and what is the marginal lift as we move from a zero-shot “health check” prompt to a forensic, hypothesis-driven audit prompt?
To isolate this variable, we held the dataset and error profile constant, injecting known errors at a flat 5% rate per type into a table of anonymized marketing data, and varied only the prompt complexity across three levels:
| Prompt Level | Description |
|---|---|
| Simple | Basic health check- explore, verify, report |
| Medium | Structured assessment organized by data quality pillars |
| Complex | Forensic audit with cross-column hypothesis testing and business context |
Results
To quantify the impact of prompt engineering, we measured the detection accuracy for each of the three prompt levels against our ground truth dataset. The table below summarizes the results:
| Metric | Simple Prompt | Medium Prompt | Complex Prompt |
|---|---|---|---|
| Structural errors detected | 3/4 | 3/4 | 4/4 |
| Logical errors detected | 1/7 | 3/7 | 4/7 |
| Total score | 4/11 (36%) | 6/11 (55%) | 8/11 (73%) |
The Simple Prompt (scoring 4 out of 11) successfully detected missing values, outliers, categorical errors, and negative metric values, but failed to detect duplicate rows and missed most cross-column logical violations. The Medium Prompt (scoring 6 out of 11) was a significant step up; it detected missing values, identified duplicate rows, and found categorical errors, while additionally detecting key funnel violations like clicks being greater than impressions and conversions being greater than clicks. The Complex Prompt (scoring 8 out of 11) was the strongest performer, achieving 100% on structural errors with forensic-level explanations. On logical errors, it detected negative metrics, two funnel violations, and video completion inconsistencies, and notably, the Auditor autonomously discovered un-injected errors, including data mapping flaws. Our key observations are as following:
- Prompt complexity directly impacts detection quality. Moving from simple to complex prompts increased total detection from 36% to 73%.
- Structural errors are easier to detect than logical errors. Even the simplest prompt found 75% of structural errors, while logical error detection ranged from 14% to 57%.
- The complex prompt exhibited emergent behavior, discovering data quality issues beyond the injected errors — validating the agent’s analytical depth. Specifically, it identified a many-to-one mapping flaw where a single campaign_id mapped to multiple campaign_names, and logical contradictions between 7-day and immediate conversion windows.
- Error analysis reveals specific failure modes. For the “Spend > 0 while Impressions = 0” error, the agent checked the inverse condition (“Impressions > 0 AND Spend = 0”), demonstrating that the agent’s logical reasoning was sound but directionally inverted. This suggests that targeted few-shot examples or tool-level guardrails could address remaining gaps.
- Certain error types remain challenging regardless of prompt level, particularly those requiring knowledge of the full marketing funnel (e.g., purchases without add-to-cart, landing page views vs. clicks). These represent areas for future improvement because evaluating complex logical anomalies requires a deep contextual understanding of domain-specific business rules. Providing this context, whether through a persistent memory system that stores historical performance baselines and funnel definitions, or via highly explicit user prompts that clearly map expected relationships, is essential for the agent to accurately validate these scenarios rather than relying on generic data logic.
Experiment 2: Table Sweep
Having identified the complex prompt as the strongest performer, we next evaluated its scaling behavior under increasing anomaly superposition: specifically, how detection performance (precision/recall trade-offs) degrades or saturates as the number of simultaneously injected error modes per table increases. While a single-error table primarily probes per-check sensitivity, production-like settings exhibit error co-occurrence and interaction effects (masking, confounding, and correlated rule violations) that can materially alter the agent’s search strategy, query budget, and false-positive propensity.
To probe this, we ran the Auditor against 11 synthetic BigQuery tables with progressively stacked error combinations — from a single isolated logical violation up to the maximum of all 7 logical and all 4 structural error types simultaneously (11 errors total per table). All runs used the complex prompt level, allowing us to map the agent’s detection ceiling as the error landscape grows increasingly complex.
Results: Per-table and Aggregate Metrics
*(Legend: L = Logical errors, S = Structural errors)
| Table | Error Profile | Expected | TP | FP | FN | F1 Score |
|---|---|---|---|---|---|---|
synthetic_1_log_error | 1L | 1 | 1 | 0 | 0 | 1.000 ✅ |
synthetic_2_log_errors | 2L | 2 | 2 | 6 | 0 | 0.400 ⚠️ |
synthetic_3_log_errors | 3L | 3 | 0 | 0 | 3 | 0.000 ❌ |
synthetic_4_log_errors | 4L | 4 | 4 | 0 | 0 | 1.000 ✅ |
synthetic_5_log_errors | 5L | 5 | 5 | 0 | 0 | 1.000 ✅ |
synthetic_6_log_errors | 6L | 6 | 6 | 0 | 0 | 1.000 ✅ |
synthetic_7_log_errors | 7L | 7 | 7 | 0 | 0 | 1.000 ✅ |
synthetic_7_log_1_struct | 7L+1S | 8 | 2 | 0 | 6 | 0.400 ⚠️ |
synthetic_7_log_2_struct | 7L+2S | 9 | 9 | 0 | 0 | 1.000 ✅ |
synthetic_7_log_3_struct | 7L+3S | 10 | 10 | 0 | 0 | 1.000 ✅ |
synthetic_7_log_4_struct | 7L+4S | 11 | 11 | 0 | 0 | 1.000 ✅ |
| Metric | Value |
|---|---|
| Perfect Detection (F1 = 1.0) | 8 / 11 tables (72.7%) |
| Total True Positives (TP) | 57 |
| Total False Positives (FP) | 6 |
| Total False Negatives (FN) | 9 |
| Overall Precision | 57 / 63 = 0.905 |
| Overall Recall | 57 / 66 = 0.864 |
| Overall F1 Score | 0.883 |
We also tested the auditor agent’s baseline ability to detect the same logical error at different prevalence levels (5%, 10%, 20%, and 40%). The agent successfully detected and accurately quantified the discrepancy at the 5%, 10%, 20% and 40% rates, demonstrating robust, range-agnostic capability that catches both rare edge cases and widespread corruption equally well. Ultimately, the results indicate that error rate prevalence does not significantly impact the agent’s detection performance when the audit completes successfully.
Finally, we ran the identical configuration three times for one table as a consistency check, and observed perfect reproducibility: the auditor consistently detected both injected errors with the same metrics and explanations across all three runs. This deterministic behavior indicates that the complex prompt configuration is stable, reducing the need for redundant audits.
Experiment 3: Memory Ablation
The previous experiments characterized the agent’s single-session capability envelope under a fixed prompt specification. In a production setting, however, auditing is inherently iterative and longitudinal: the agent re-encounters the same schemas, recurring anomaly modes, and known “benign” deviations across repeated runs. This motivates a key question: does persistent, user-scoped memory (i.e., accumulated priors from prior audits) measurably improve detection performance and efficiency over time by biasing the agent toward higher-yield checks, reinstating domain-specific invariants without re-deriving them from scratch?
To isolate the contribution of the long-term Memory Bank, we ran the agent twice on the same table under identical conditions, first with no prior context (cold start) and then with memories loaded from previous audit sessions. We evaluated the agent on a synthetic table (synthetic_7_log_4_struct) containing 7,999 rows, deliberately corrupted with 11 distinct error types (4 structural, 7 logical) at a ~5% error rate. The two conditions differed only in whether the agent had access to its Memory Bank before beginning the audit.
Results
Without memory, the agent received a minimalist zero-shot prompt (“Check if there are any errors for table X?”) and relied solely on exploratory analysis. Under these cold-start conditions, it achieved an overall detection rate of 45% (5/11), identifying 2 of 4 structural errors and 3 of 7 logical errors.
When the same agent was instructed to load past context (“load memories about auditing tables…”), the results improved dramatically. By retrieving specific logical checks and known error patterns from prior sessions, the memory-augmented agent achieved a 91% detection rate (10/11) — a 102% relative improvement over the baseline.
Structural error detection reached a perfect 100% (4/4), while logical error detection rose from 43% to 86% (6/7), successfully uncovering complex violations such as negative metric values and spend recorded against zero impressions.

The figure shows a clear performance gap between the memory-augmented agent (blue) and the baseline agent without memory (red). For structural errors, memory enabled perfect detection (100%) compared to 50% without memory. For logical errors, memory improved detection from 43% to 86%, demonstrating that access to prior audit patterns and domain knowledge substantially enhances the agent’s ability to identify complex data quality issues beyond basic exploratory analysis.
The sole undetected error was a funnel sequence violation (purchases without add-to-cart). Notably, the agent did not simply miss this check — it correctly reasoned that the validation was impossible given the aggregated schema, which lacked the transaction-level granularity required to verify a purchase-to-cart relationship. This suggests the miss was an analytically sound decision rather than a detection failure.
Memory vs. Prompt Complexity
These results raise an important nuance: if a prompt is already sufficiently detailed and structurally prescriptive (as in our complex prompt from Experiment 1), the memory module provides only marginal uplift. However, memory becomes highly valuable in continuous operational scenarios, where its benefits compound over time:
- Adaptability: The agent iteratively learns from past edge cases, refining its checks with each audit cycle.
- Contextual Awareness: It builds a deep, automated understanding of project-specific business rules and historically common data quality issues.
- Consistency & Efficiency: Audit coverage remains stable across sessions, with fewer redundant exploratory queries needed to reach comprehensive detection.
Cloud Deployment
The system is deployed as a production-grade, cloud-native service on Google Cloud, following a containerized, infrastructure-as-code workflow from local development through to automated CI/CD and managed compute.
CI/CD Pipeline
The project uses a fully automated Bitbucket Pipelines CI/CD pipeline with two distinct execution stages:
- On Pull Request: Automated linting and static analysis run immediately to enforce code quality standards before any merge is permitted.
- On Merge to
main: The pipeline builds two independent Docker images — one for the headless A2A API backend, one for the interactive web UI — pushes both to Google Artifact Registry, and triggers rolling deployments to their respective Cloud Run services. All runtime configuration (model identifiers, dataset IDs, memory service URIs, Cloud Storage bucket names) is injected exclusively via environment variables, ensuring no secrets or environment-specific values are hardcoded into the images.
Dual-Service Deployment Architecture
The agent is deployed as two independent, containerized Cloud Run services, each built from its own Dockerfile and serving a distinct class of consumer:
Service 1 — A2A API Backend
The backend service exposes a headless Agent-to-Agent (A2A) interface — an open, HTTP-based protocol designed for agent interoperability across frameworks. It publishes an Agent Card (a structured capability manifest) that allows any external service or AI agent to programmatically discover what the Data Quality Agent can do without requiring any knowledge of the underlying ADK implementation.
Clients interact with the backend by sending structured JSON-RPC messages over standard HTTP. This means the auditor can be:
- Integrated into classical data pipelines (like Airflow or dbt) to trigger automatic quality checks.
- Orchestrated by other AI agents as part of a larger, automated workflow.
- Invoked from any programming language, completely independent of the underlying Python stack.
- Embedded in CI/CD or alerting systems using simple HTTP requests.
Service 2 — Interactive Web UI
The web UI service hosts an interactive conversational frontend, allowing data engineers and data scientists to interact directly with the full agent system through a browser. It communicates with the agent backend and provides a session-aware interface where users can issue audit requests, review structured findings, retrieve generated reports, and provide manual corrections that are subsequently persisted to the Memory Bank.
Google Cloud Agent Engine provides shared, persistent session storage for both services, ensuring that conversation context and session state survive container restarts and instance scale-out events.
Conclusion
This report demonstrates a highly effective and intelligent agent for automating data quality assurance, utilizing a long-term memory architecture that not only frees up valuable engineering resources but also gets smarter with every interaction. By reclaiming data engineering bandwidth, it liberates engineers to focus on building infrastructure rather than performing manual data QA. Furthermore, it drives shift-left quality by catching errors in BigQuery tables before data scientists spend hours training models on corrupted data. Ultimately, this compound intelligence ensures the system never resets; instead, every manual correction and interaction makes the auditor permanently better and more adapted to our data ecosystem.
Lessons Learned
- Test with Synthetic Data First: Without a meticulously crafted synthetic dataset, we would have had no objective way to measure if our prompt strategies were improving the agent’s performance.
- Memory is Context, Context is King: The ability to retrieve facts from past runs—remembering past errors, user feedback, and specific constraints—is what elevates a simple bot to a true Co-Pilot.
- Start Specific, Then Generalize: We focused on nailing the Auditor Agent’s specific use case with BigQuery first. This created a robust foundation before we expanded to other functions like report generation.
- Leverage a Unified Cloud Ecosystem: Building entirely on Google Cloud services — ADK, Vertex AI, BigQuery, Cloud Run, Cloud Storage — eliminated integration friction between components and allowed us to move from prototype to production deployment without stitching together tools from multiple vendors.