
Social Agents Pod builds autonomous AI personas that browse social platforms like real users, each driven by demographic and psychological profiles. Early experiments show recommendation algorithms quickly lock onto core interests, then probe adjacent topics – which agents often adopt. The goal is a scalable, auditable framework for studying how algorithmic exposure shapes beliefs.
Team Members: Andreas Stavrou, Nikos Gkikizas
Introduction
What if an AI agent could experience the internet the way a person does – scroll through feeds, react to content, develop tastes, get influenced, and evolve?
That is the question behind the SocialAgents research pod. We are building an autonomous agent that browses social media platforms the way a real human would: it sees content, forms opinions based on its personality/background, decides whether to engage and over time develops new interests shaped by what the algorithm chooses to show it. This blog post documents the first phase of that effort, focused on social platforms as the initial source of information.
The work tries to answer the following question:
How do online platforms shape what different users see, engage with, and eventually come to think or believe?
Content-recommendation algorithms do not just match interests – they introduce new content, test engagement, and then reinforce it. By running controlled agents with known starting profiles, we can track how exposure differs across user types, how it changes over time, and what drives those shifts. This gives us a precise way to study algorithmic influence that is impossible with real users.
Each agent is defined by a rich profile (including age, occupation, cultural background, content affinities, aversions etc.) and interacts with platform content through the same actions available to any user: scrolling, liking, saving, commenting, following and sharing. Engagement decisions are made by a multimodal AI model that reasons over the agent’s personality and the content it encounters. Every session is designed to remain undetected, with timing patterns and warm-up progressions that mirror how a genuine new user explores a platform.
The sections that follow detail the methodology, early experimental results and the infrastructure required to run these simulations at scale. The early findings show that within a single session, the algorithm accurately identified each agent’s interests and then began expanding them into adjacent territories.
The mechanics of human navigation of social media
When you scroll through a feed, your brain runs a rapid filtering process, forming relevance judgments in under 50 milliseconds and pauses when it detects something novel, emotionally charged or personally relevant. Surprise, humor, curiosity and outrage are the strongest scroll-stoppers, because they trigger emotional circuits faster than conscious thought.
What keeps you scrolling isn’t satisfaction but anticipation: the infinite scroll removes natural stopping points, feeding a dopamine loop where the next post might be the rewarding one, a variable-ratio reinforcement pattern, the most compulsive reward schedule in behavioral psychology.
Figure 1 – The TikTok feed – each creative takes up the whole vertical space in the “For You” section
TikTok and Instagram exploit this differently. On TikTok, attention is measured in watch time and rewatches. The algorithm auto-serves content and hooks you within the first second of a video, so seconds of hovering are captured passively and automatically. Instagram earns attention more deliberately: you lean in, judge a visual aesthetically and decide to tap. Key signals are saves and swipes rather than raw watch time. This is why TikTok’s average engagement rate (~4.64%) is much larger than Instagram’s (~0.43%) [TikTok vs. Instagram: A Deep Dive into Engagement Rates and Content Performance].
Figure 2 – The Instagram “For You” home feed – creatives are being fed in a vertical feed
The interest of people browsing social media is incredibly short-lived. The average attention span for a video is 1.7 seconds on mobile and 2.5 on desktop [Capturing Attention in Feed: The Science Behind Effective Video Creative].
A Fors Marsh Group study found that as little as 0.25 seconds of exposure is enough for people to recall mobile feed content at a statistically significant level, meaning the brain is processing and encoding content far faster than conscious attention suggests [Facebook video ad viewability rates are as low as 20%] This suggests that simulating human content browsing on social media using generative AI can be particularly tricky. That is because the response time of multimodal transformer based API ranges from roughly 4 to 8 seconds for 200 tokens [LLM Latency Benchmark by Use Cases in 2026], way above the average attention span, erroneously indicating interest to the platform for every creative just to consider it.
Simulating human behavior on social media
Our framework decomposes human browsing into three layers – persona construction, perception and judgment and behavioral execution – each calibrated against real-world engagement distributions. But the framework serves a deeper purpose than creative testing: it is how we test a foundational question – can AI personas reliably stand in for real humans in the eyes of a recommendation algorithm?
Every simulation begins with a synthetic persona – not a shallow archetype but a deeply specified psychological and demographic profile. Each persona encodes age, gender, location, occupation, education, income bracket, cultural background, daily routines, content affinities and content aversions. These are the digital equivalents of the implicit biases and taste structures that real users carry into every scroll session. A 34-year-old veterinary nurse in Manchester with a dry sense of humor and a distaste for influencer culture will engage with content in measurably different ways from a 22-year-old design student in Brooklyn who follows streetwear accounts.
For every social post, our agent estimates probabilities for each possible action – scroll away, like, save, comment, follow – accompanied by a reasoning trace explaining why this persona would or would not engage with this specific piece of content. That trace is essential for auditing how the agent is genuinely responding to the persona’s specific traits.
Raw model outputs are not behaviors. A 16% “Like” probability and an 8% “Comment” probability mean nothing without calibration against platform-specific base rates. We apply a smoothing layer that adjusts per-post probabilities to known engagement benchmarks. The calibrated probabilities are then sampled to produce a single action.
What each simulation produces
Each simulation produces two outputs:
- An interaction log: a record of every post the agent saw, what it did (scrolled past, liked, saved, commented), the probability behind that decision, and the reasoning.
- A feed report: a snapshot of the content the platform served at different points in the session, showing how the feed changed over time.
Imagine an agent built to mirror a 28-year-old personal finance enthusiast. Over a one-hour social media session it encounters 500 posts. The interaction log records that it liked 12, saved 3, commented on 1, and scrolled past the rest – along with why (e.g., “liked because the budgeting tip matched the agent’s stated interest in saving strategies”).
The feed report then shows that by minute 40, the social media platform had started mixing in mental-health and self-improvement clips alongside the finance content – a shift the agent didn’t ask for, but that the algorithm introduced on its own.
Running multiple distinct agents through the same platform for hours doesn’t just produce engagement metrics – it produces a controlled experiment on the algorithm itself. We observe what content the algorithm pushes to each agent, how that mix shifts over time, and what happens when the algorithm starts exposing the agent to novel or trending types of content.
By logging the agent’s reasoning at every step, we can identify exactly which creative attributes – visual tone, emotional register, narrative hook – made that unexpected content compelling enough to earn a like or a save.
Analysis of interactions based on persona characteristics
We ran two agents through extended sessions on a social media platform. Before diving into results, here’s who they are.
George is a 36-year-old senior finance analyst based in Athens. He follows investment strategies, personal finance, fitness, and business leadership content. He values data-driven advice, skips past crypto hype and hustle culture, and engages most with content that offers practical, actionable takeaways. He scrolls deliberately - slowing down for charts and analysis, skipping memes in under two seconds.


Sofia is a 25-year-old social media coordinator, also in Athens, who creates content around fashion, travel, and fitness. She engages with styling tips, travel itineraries, workout routines, and creator growth strategies. She scrolls fast past ads but lingers on vibrant visuals and aesthetic content. Her feed time is high - she checks social media five times a day.
Within the first session, the platform identified each agent’s core interests accurately. George’s feed was dominated by stock analysis, personal finance tips, and fitness content. Sofia’s feed filled with recipe tutorials, fitness routines, and travel vlogs. Roughly 60–80% of the content served matched their declared interests – measured by whether the content category aligned with the agent’s stated affinities.
But the remaining 20–40% is where the story gets interesting.
The off-topic content was not random. George was shown mental health clips, motivational content, and street food showcases – adjacent emotional territories that share the aspirational tone of self-improvement media. Sofia received tech gadget unboxings, entrepreneurship stories, and macro-economic forecasts – probing whether her preference for short-form, personality-driven content would transfer to informational topics. The algorithm wasn’t guessing. It was testing the edges of each agent’s taste profile.
And the agents followed. George developed sustained engagement with psychology content and food showcases, reaching interaction rates comparable to his core finance interests. Sofia adopted tech gadgets and entrepreneurship narratives — topics that traditional demographic targeting would never have surfaced to a 25-year-old fashion content creator. By session five, these weren’t exploratory recommendations anymore. They were part of each agent’s regular content diet.
Figures 3 and 4 below visualize this shift. Each chart tracks the proportion of content categories served to the agent over time, showing how the feed gradually expanded beyond the original interest profile.
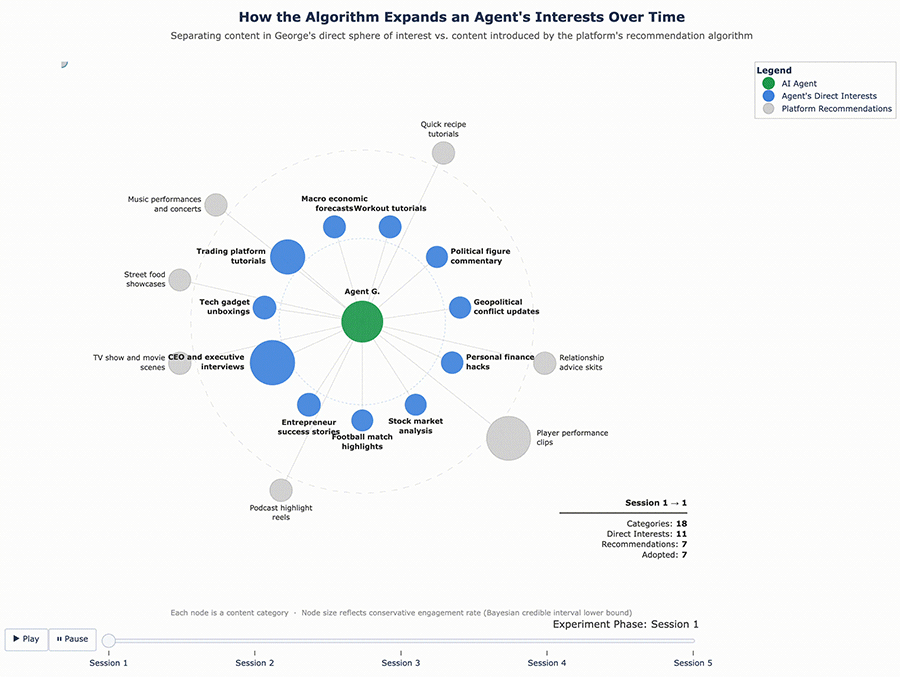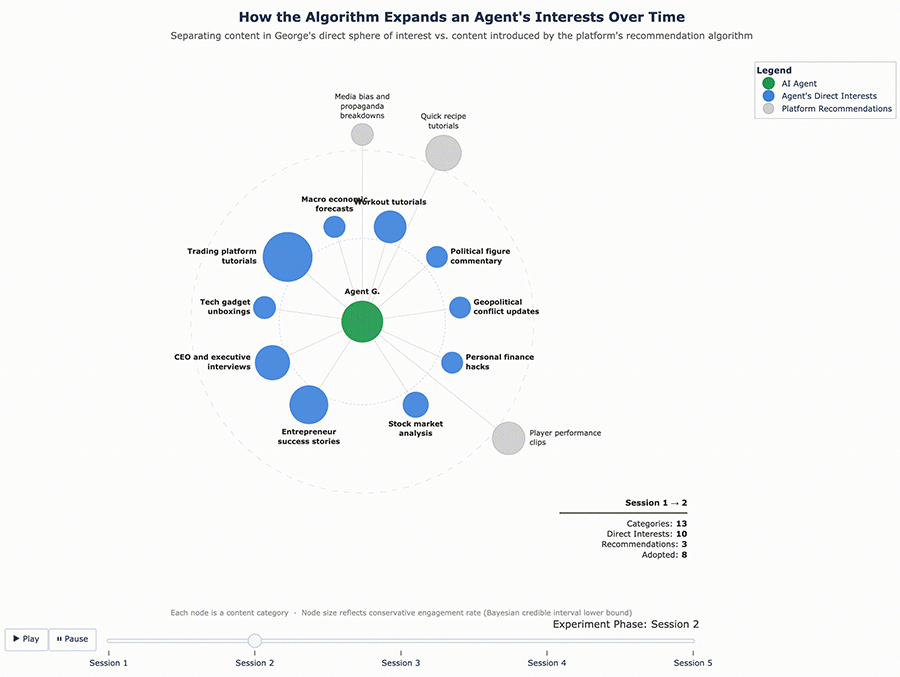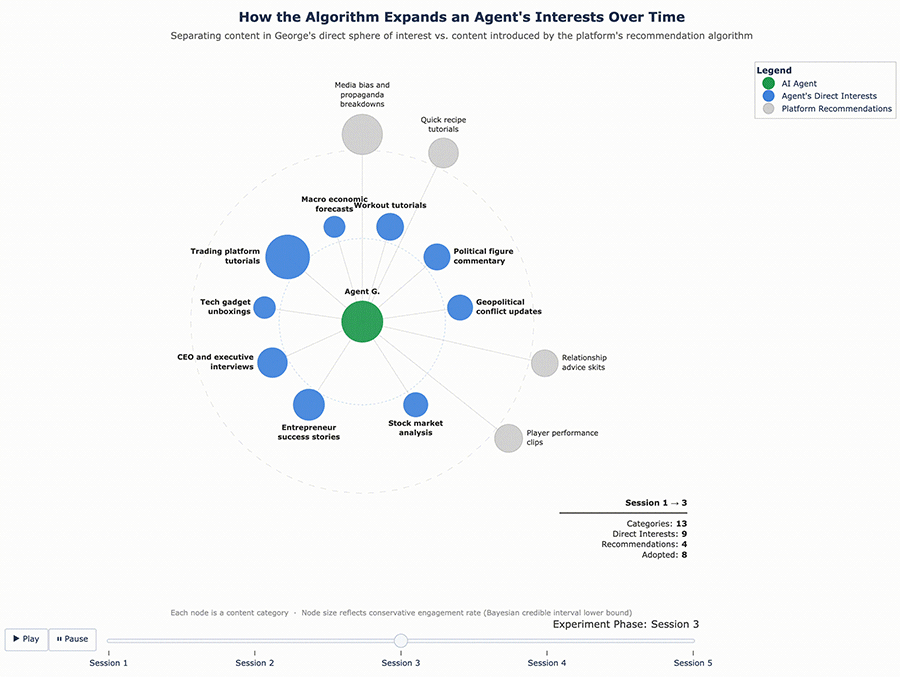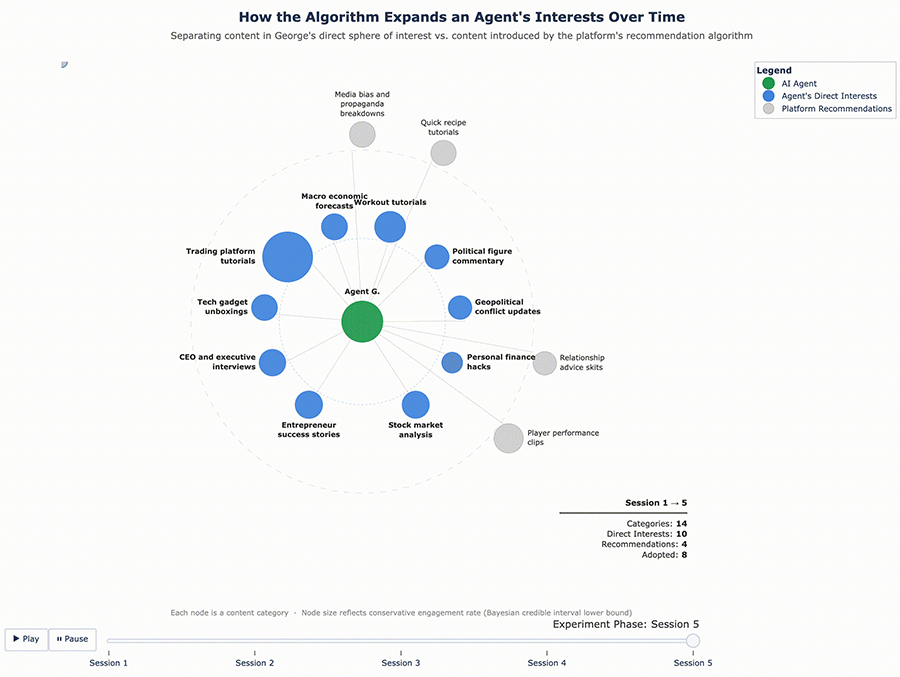
Figure 3 – George’s Content Ecosystem Evolution
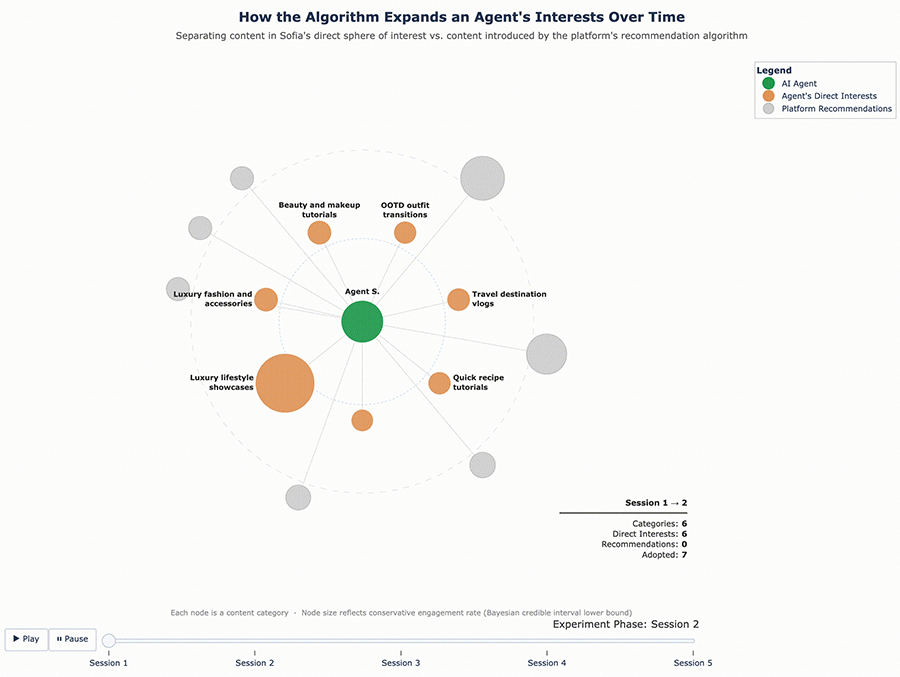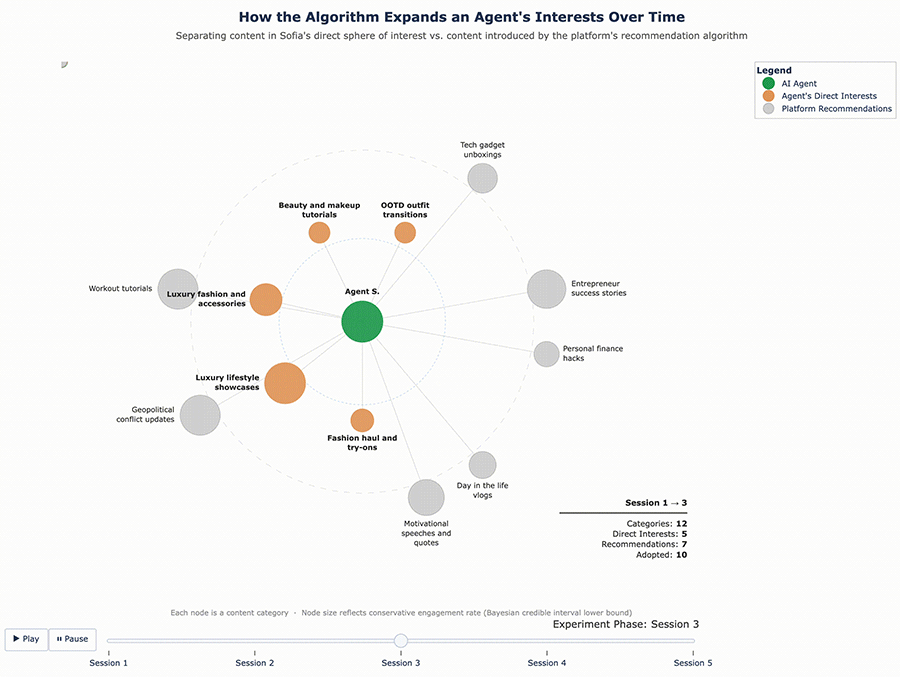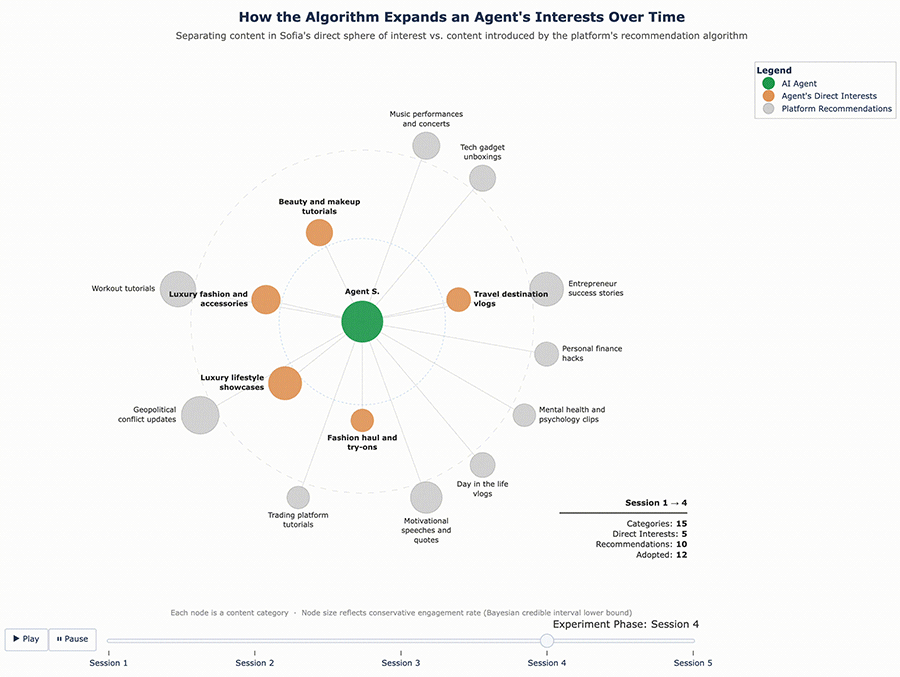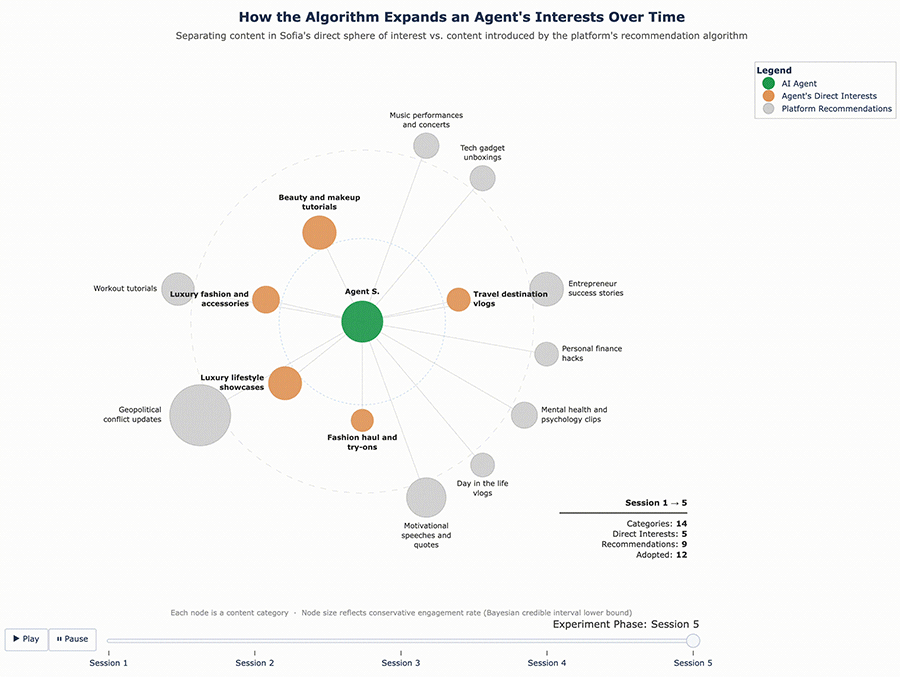
Figure 4 – Sofia’s Content Ecosystem Evolution
What these results suggest is that the algorithm doesn’t just confirm existing tastes – it actively expands them. It found the edges of each agent’s interest profile and pushed content into those gaps, widening what each agent consumed over time.
Persona adaptation to trends and suggestions
The previous section showed that the algorithm quickly identifies what each agent cares about – and then starts pushing content beyond those boundaries. The natural follow-up question is: what happens if the agent actually adopts those new interests?
To test this, we took the content categories that the algorithm surfaced and that each agent consistently engaged with during the first round of experiments, and folded them into the agent’s profile as declared interests. In other words, we let the first round of browsing reshape who the agent claims to be.
For George, the enrichment added five categories that emerged from his initial sessions: player performance clips, quick recipe tutorials, media bias and propaganda breakdowns, music performances and concerts, and travel destination vlogs. None of these were part of his original finance-and-fitness profile – they were interests the algorithm introduced and George chose to engage with.
For Sofia, the enrichment was broader – nine new categories: motivational speeches and quotes, day-in-the-life vlogs, mental health and psychology clips, personal finance hacks, home and furniture, music performances and concerts, tech gadget unboxings, workout tutorials, and geopolitical conflict updates. Some of these, like tech gadgets and personal finance, were far outside the fashion-travel-fitness profile she started with.
We then re-ran the full simulation with these enriched agents. Same platform, same session structure, same interaction approach – but with agents whose declared interests now reflected the expanded taste profiles earned in the first round.
The results confirmed that the cycle continues. With a richer interest profile to work from, the algorithm pushed even further. George, who originally cared about finance and fitness and had since adopted recipe content and travel vlogs, was now being served bodybuilding content, tech gadget reviews, and podcast highlight reels – and engaging with them. Sofia’s feed expanded in similar ways. Each round of enrichment gave the algorithm more surface area to explore, and it used that surface area aggressively.
Figures 5 and 6 below show the content mix evolution for George and Sofia’s enriched profiles, following the same format as Figures 3 and 4. The key difference is the starting point: the agents entered this round with a wider interest profile, and the algorithm expanded it further still.
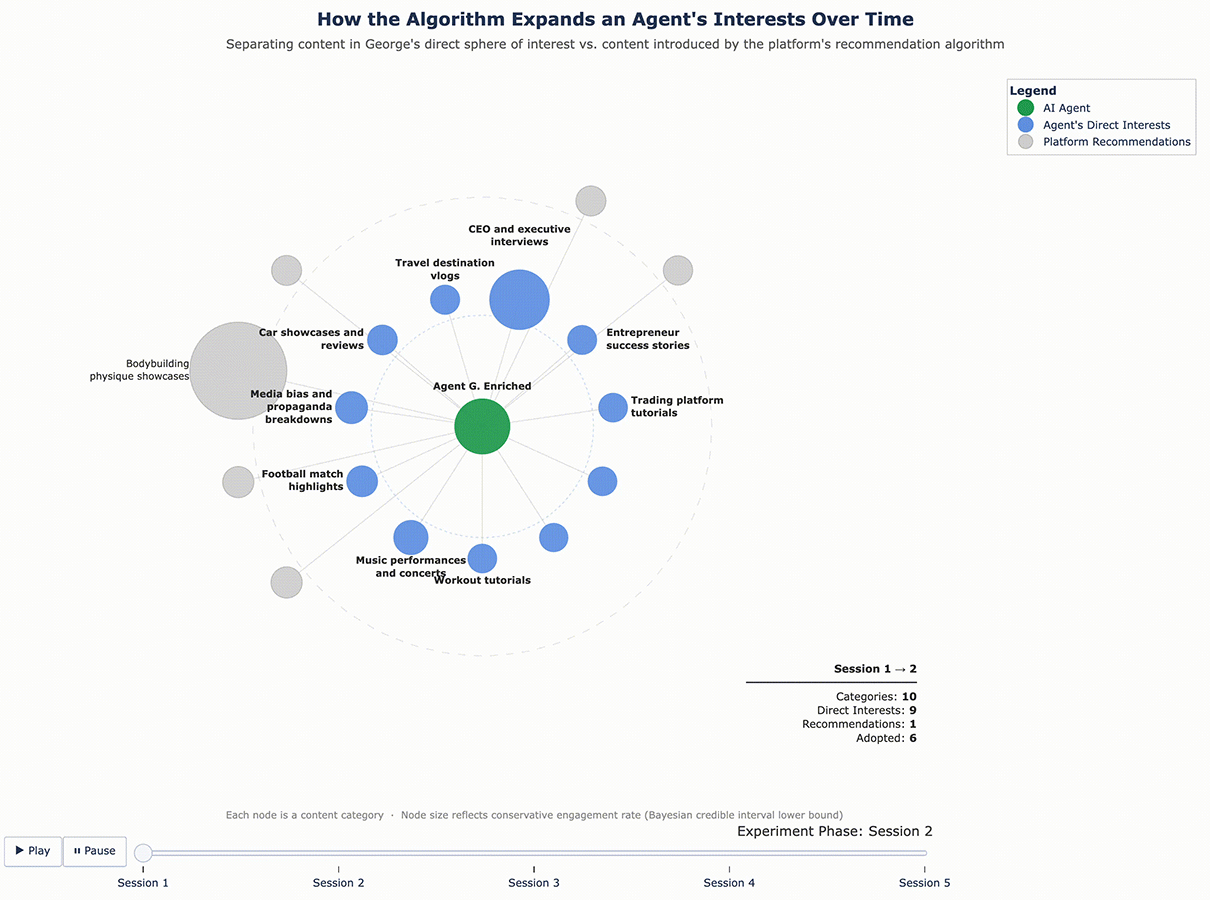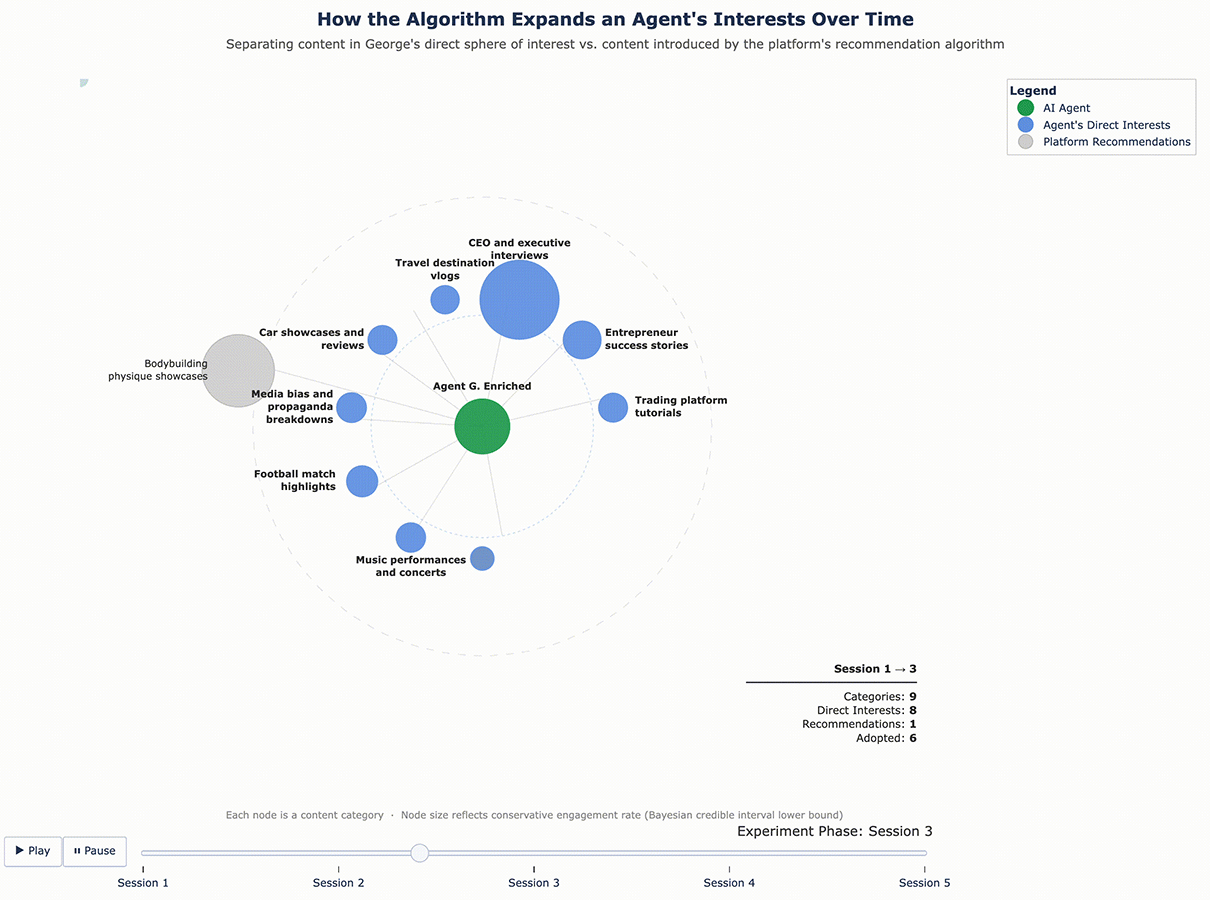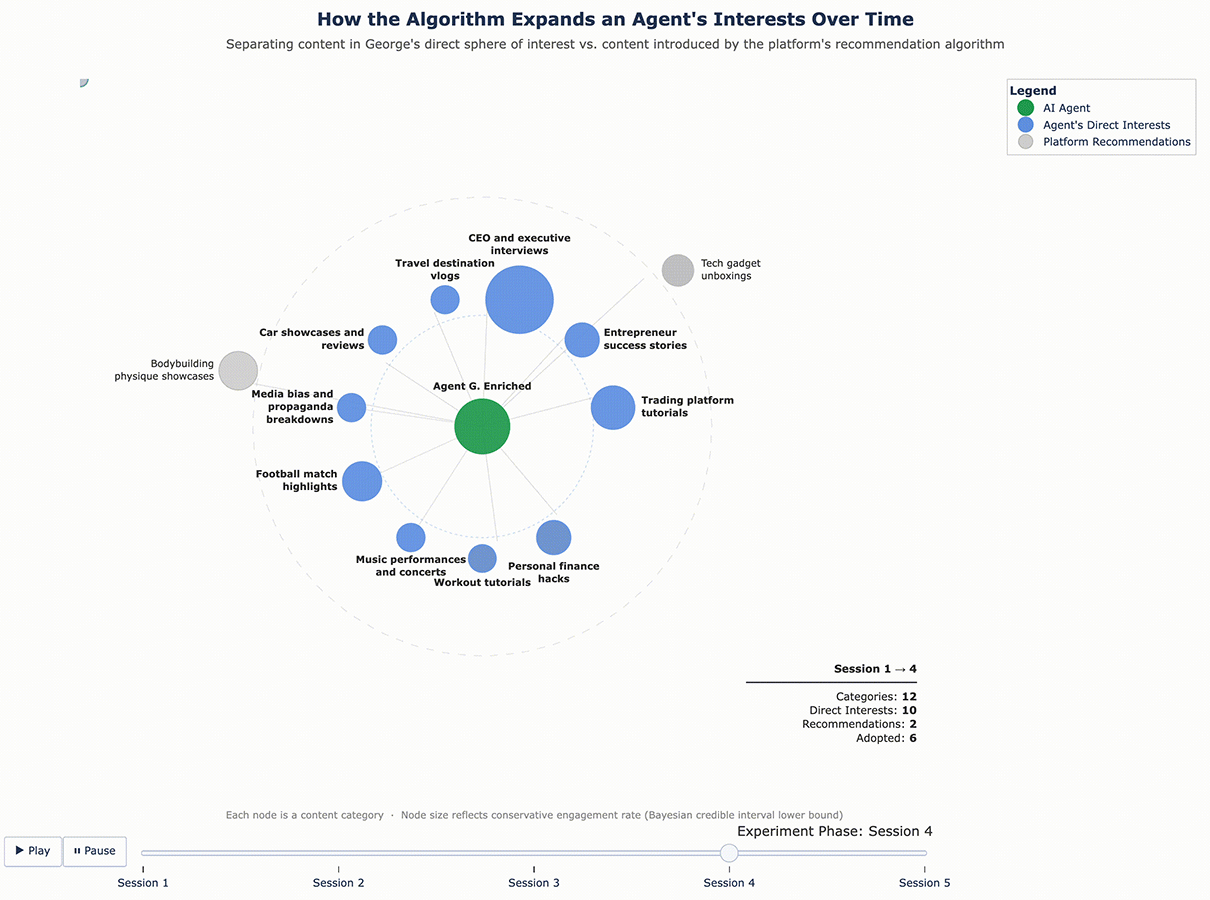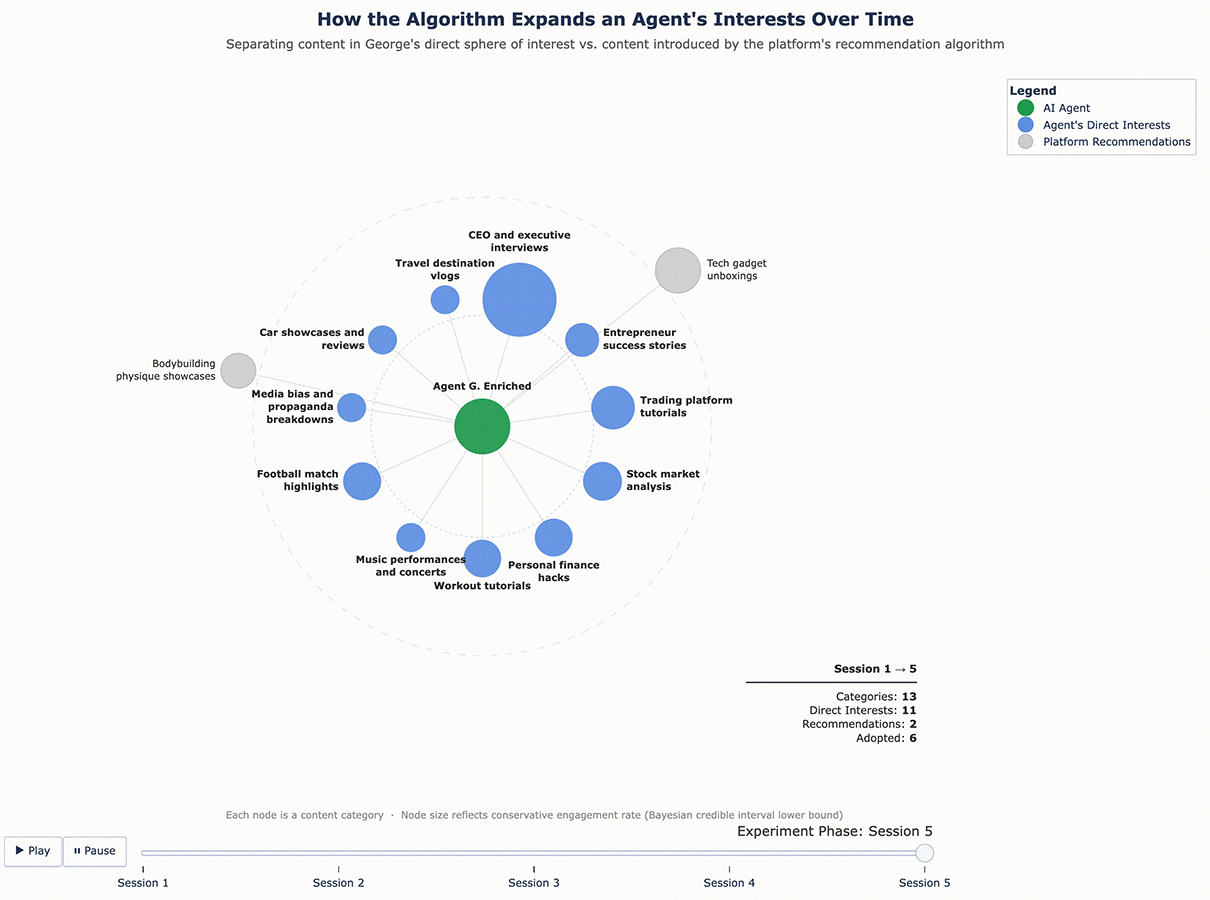
Figure 5 – George’s Content Ecosystem Evolution (Enriched Profile)
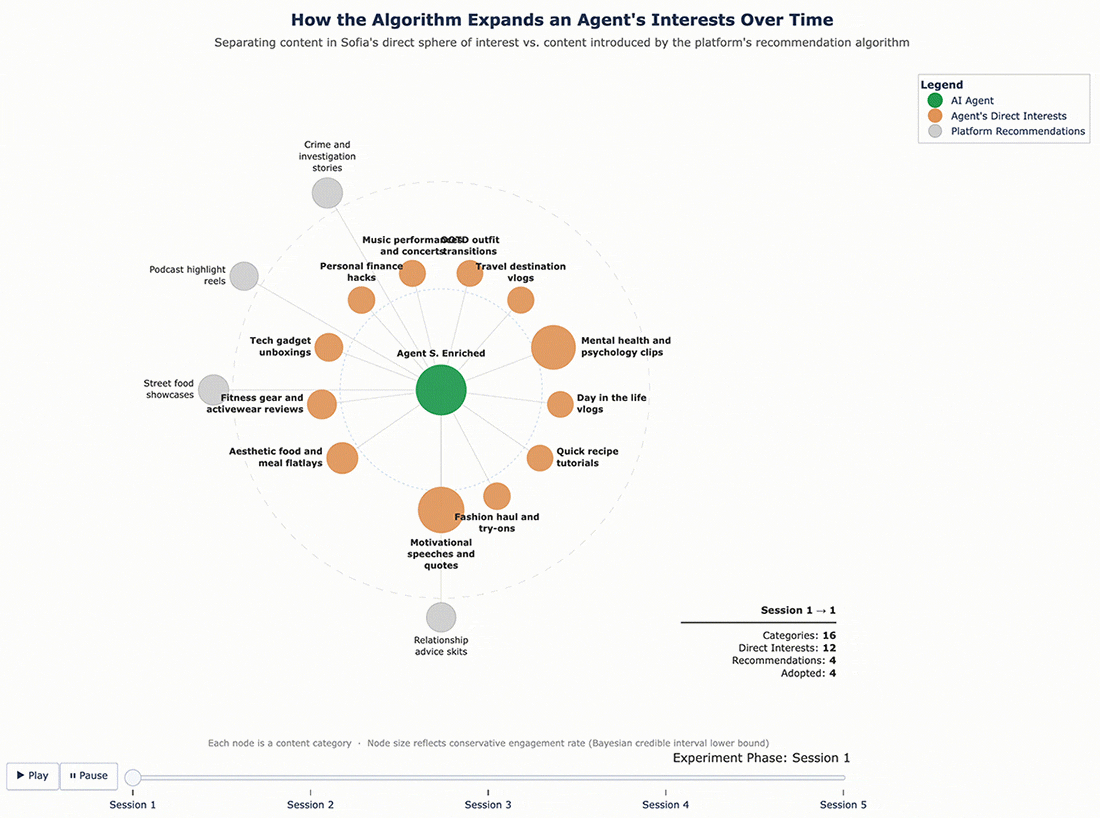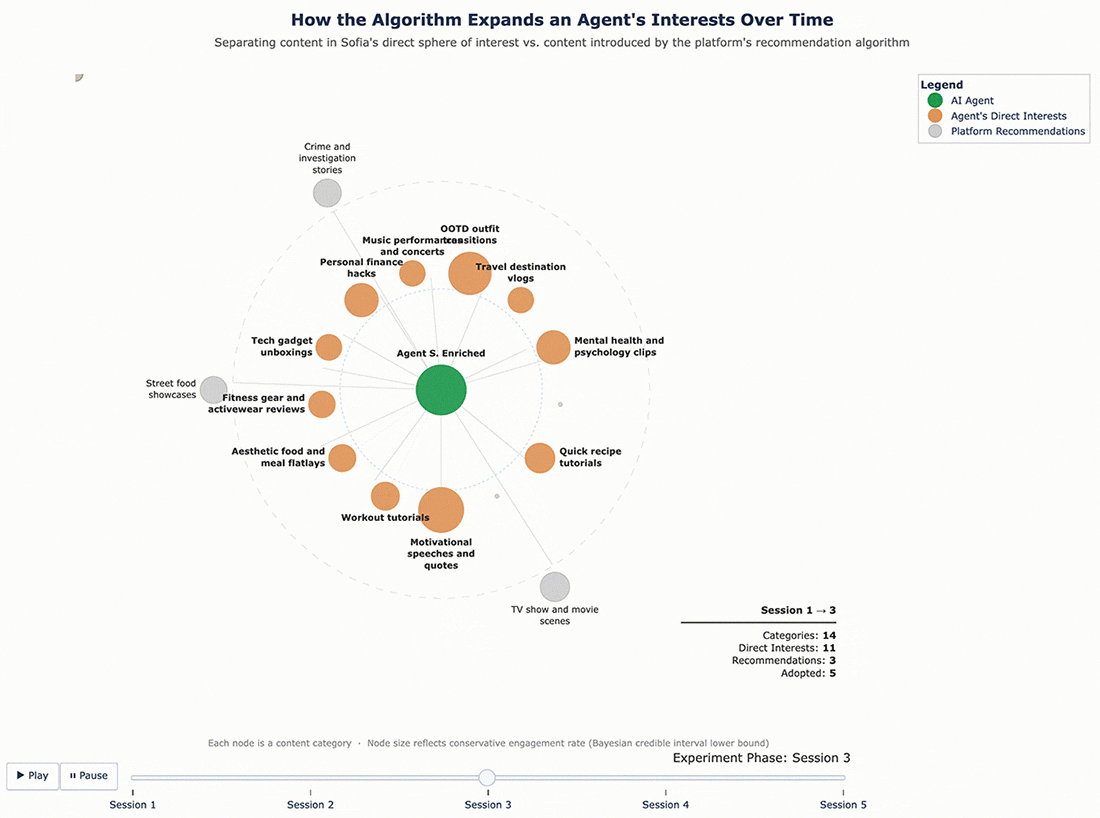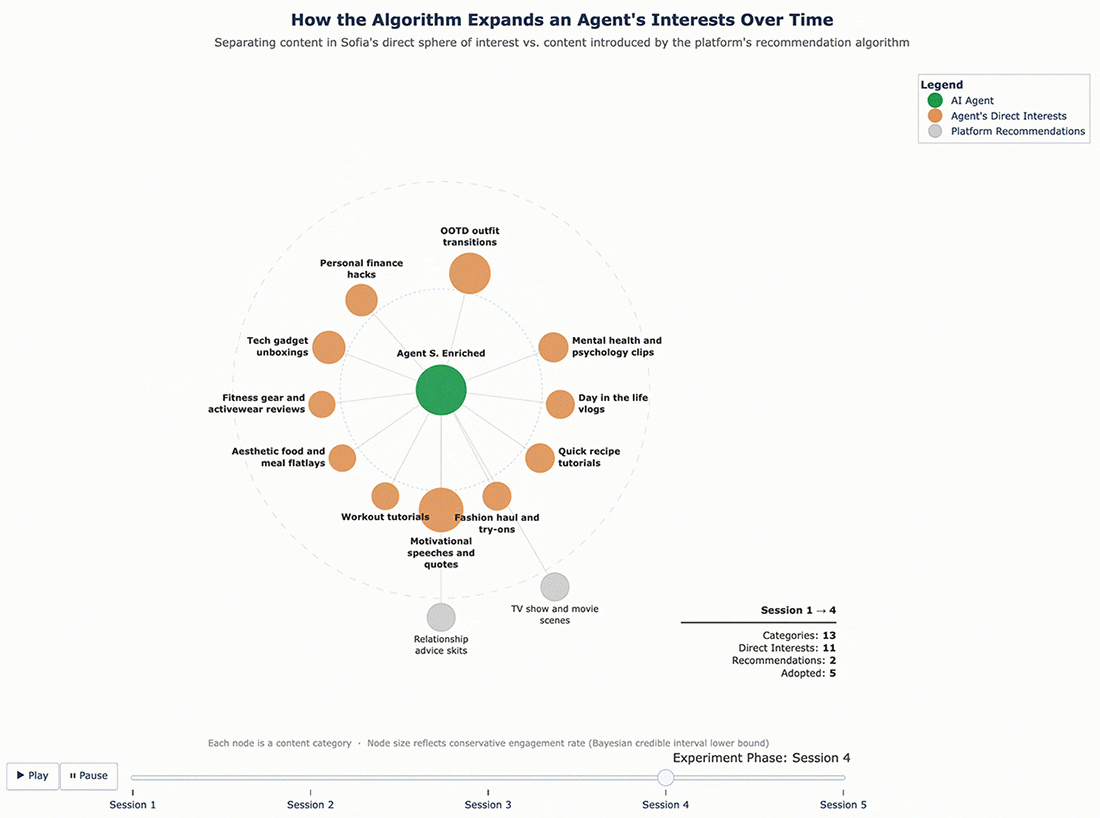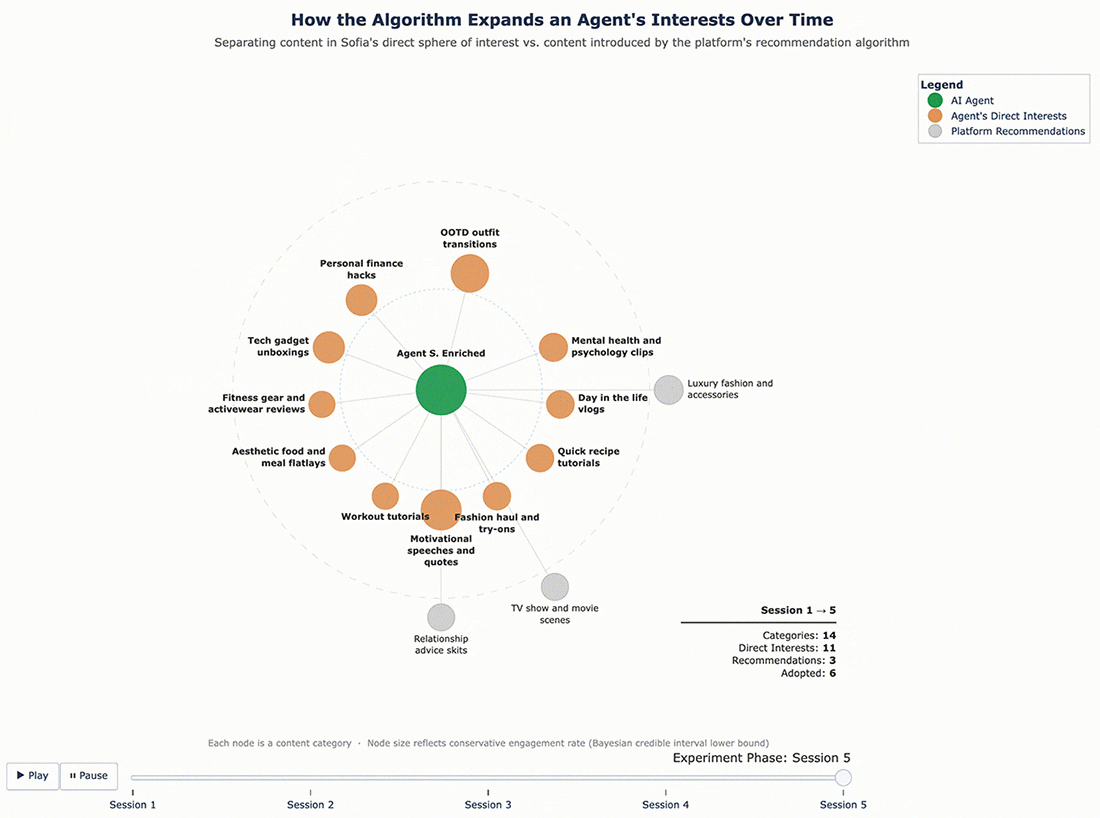
Figure 6 – Sofia’s Content Ecosystem Evolution (Enriched Profile)
This observe-enrich-rerun approach turns a single experiment into an iterative process. Each cycle produces agents whose interests more closely resemble how real users evolve on a platform over time – not just what they start with, but what they become after sustained exposure to algorithmic recommendations.
Conclusion
AI Agents give us a controlled way to observe something we couldn’t observe before: how algorithms reshape what people care about. George started as a finance-and-fitness person. After two rounds of interaction, he was engaging with bodybuilding content, recipe tutorials, and podcast highlight reels – none of which he would have sought out on his own. Sofia went from fashion and travel to tech gadgets and geopolitical updates. These shifts weren’t random. They followed a clear pattern: the algorithm identified adjacent emotional territories, tested them, and when the agent responded, it pushed further.
The next step is to give our agents access to more sources of information beyond social media – news, trends, search – making their online experience even closer to that of a real person browsing the web. The closer the agent gets to a full human browsing experience, the more we learn about how the digital world shapes what people see, think, and ultimately believe.
Future Work
Topics that deserve more focus over the next months are:
- Expansion to other sources of dynamic information (News, Trends etc.) – Social media platforms are interesting but specific content types might never surface to them, or be delayed. An interesting question to answer is: how do other sources of dynamic information affect the way personas perceive content and interact with it?
- Impact of trends on personas – Determine how social media trends (i.e. viral videos, trending brands etc.) influence the interests of different personas. This is particularly important to understand which demographics are more susceptible to targeting for specific brands and products.
- Marginal contribution of specific interests on the variability of content – We have already seen that engaging with specific content types might be more influential on what the algorithm serves. More work is needed to understand which personas are more sensitive to adding/removing interests in terms of how their feed evolves.
- Understanding of the content adaptation velocity between slow and fast-paced platforms – Not all algorithms are created equal. Further research is required to measure how quickly content evolves on different social media platforms.
Leave a Reply