Artificial intelligence is experiencing a moment of unprecedented attention. New models appear almost weekly, and headlines regularly promise that AI will transform every industry. Large Language Models (LLMs)—the technology behind conversational systems like ChatGPT—have demonstrated remarkable abilities to write, summarize, reason, and interpret complex information.
But beneath the excitement lies a practical business question:
Can these new GenAI systems actually outperform the specialized machine learning models that companies already rely on?
At WPP AI Lab, we decided to answer that question using the gold standard for applied engineering and science: through empirical experimentation.
Rather than relying on claims or assumptions, we conducted an in-house investigation designed to evaluate whether modern AI models could improve one of the most important functions in marketing: predicting campaign success.
The results were revealing.
We discovered that large language models can rival highly specialized systems—but only when applied in the right way. The key was not simply choosing the most powerful model, but designing the correct architecture and training strategy around it.
This article tells the story of that journey: the problem we set out to solve, the challenges we encountered, the models we tested, and the lessons we learned about how AI can deliver real business value.
The Motivation: Turning Marketing Insight Into Prediction
Marketing has always combined creativity with data. Campaigns are built on ideas—stories that connect brands with audiences—but their success ultimately depends on how well those ideas resonate in the real world.
Marketers must make decisions about many interconnected factors:

- Who the campaign targets
- How the brand is positioned
- What message the creative communicates
- Where the campaign is distributed
- Which markets it reaches
Each of these factors influences how audiences respond.
Traditionally, organizations attempt to manage this complexity through specialized machine learning models. These models analyse historical data and identify patterns associated with successful campaigns.
Over time, they can become highly effective prediction engines.
However, they also have limitations. Most traditional systems require structured inputs, carefully engineered features, and extensive retraining whenever new signals are introduced.
Meanwhile, a new generation of AI models has emerged with a very different capability. Large language models are trained on enormous amounts of text and information, giving them an ability to interpret complex descriptions and contextual relationships.
This raised an intriguing possibility.
Instead of forcing marketing data into rigid modelling structures, could AI models directly interpret the narrative descriptions behind campaigns and predict their outcomes?
If so, the implications would be significant. Marketers could evaluate campaign ideas before launch, test creative variations more rapidly, and gain deeper insight into why certain strategies succeed.
But before adopting such technology, we needed to determine whether it could truly match the performance of the systems already in use.
The Challenge: Predicting Campaign Performance
To explore this question, we designed a controlled experiment around an actual marketing prediction problem.
To ensure robust and repeatable results, we utilized proprietary synthetic datasets designed to mirror real-world marketing dynamics, allowing full control and visibility over the factors driving campaign performance.
Each campaign in our dataset was described using five key components:
Audience – the consumer segment being targeted
Brand – the positioning and perception of the brand
Creative – the tone and message of the campaign
Platform – where the campaign runs
Geography – the markets being targeted
Based on these characteristics, campaigns were classified into one of three outcomes:
- Overperforming
- Average performance
- Underperforming
Our task was to train AI systems capable of predicting the likely performance category of a campaign.
To make the challenge realistic, we introduced an important complication.
In real marketing environments, most campaigns perform roughly as expected. Only a small proportion dramatically outperform or significantly underperform.
We recreated this condition by generating datasets where “average performance” campaigns were far more common than the other two categories.
This imbalance creates a difficult prediction problem. Many models simply learn to predict the most common outcome rather than identifying the subtle patterns that signal exceptional success or failure.
Any model that succeeded in this environment would therefore need to detect nuanced relationships between campaign characteristics.
Our Approach: Testing Three AI Strategies
Rather than evaluating a single system, we designed our experiment to test three different strategic approaches to applying modern AI.
Each strategy tested represented a different balance between speed, flexibility, and customization.
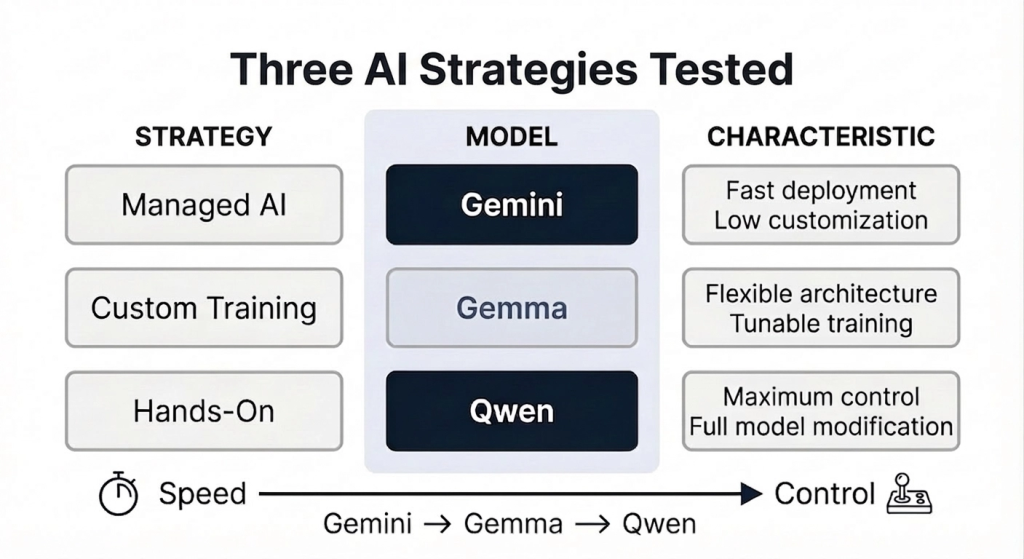
Strategy 1: The Managed Model
The first strategy relied on a fully managed AI platform using Gemini 2.5 Flash-Lite, developed by Google.
This approach offered the fastest path to experimentation. The model could be fine-tuned quickly using cloud infrastructure without needing to build custom training systems.
From a business perspective, this kind of solution is attractive because it minimizes engineering overhead and enables rapid prototyping.
However, it also limits how much control teams have over how the model learns and makes decisions.
We used this workflow to establish a baseline: how well could a modern AI model perform with minimal customization?
Strategy 2: The Customizable Model
Our second strategy used Gemma, another model developed by Google, but released with open weights.
Open-weight models provide much greater flexibility. Instead of relying on a predefined training pipeline, we could directly control how the model was further trained on our datasets and how it generated predictions.
This allowed us to reshape the system so that it behaved more like a structured decision engine rather than a conversational AI.
The additional control proved crucial.
By carefully designing how the model made predictions, we were able to prevent it from defaulting to the most common outcome and instead encourage it to learn the deeper relationships within the data.
Strategy 3: The Fully Hands-On Modeling Approach
Our final strategy pushed customization even further.
Using Qwen3, developed by Alibaba Cloud, we built a completely custom training environment and directly modified parts of the model’s architecture.
This approach allowed us to reshape the model into a dedicated classifier that could only produce the specific categories required by our task.
While this workflow required significantly more engineering effort, it provided the highest degree of flexibility and experimentation.
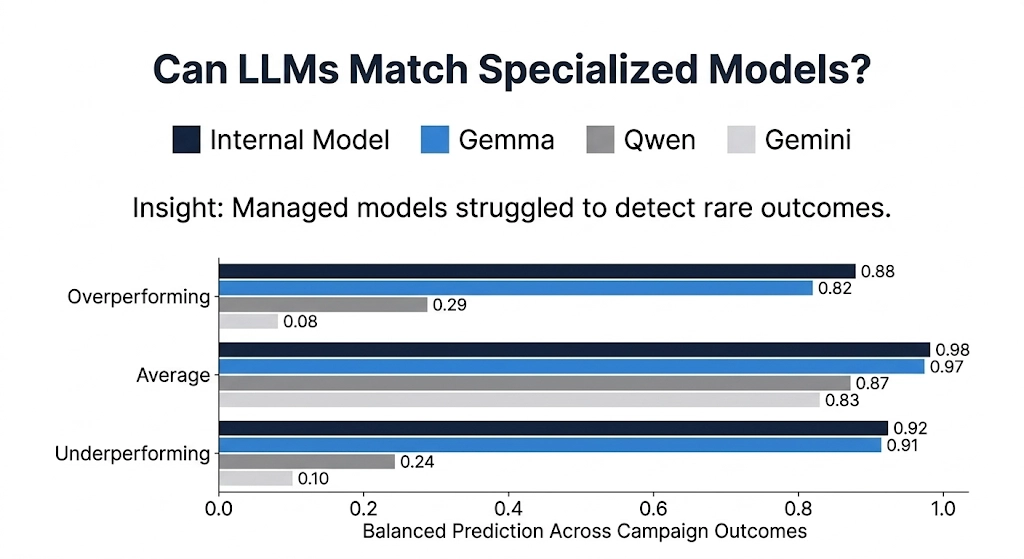
The Results: A Clear Winner Emerges
When we compared the results across all three systems, the differences were striking.
The managed Gemini workflow proved easy to deploy but struggled with the imbalance in our dataset. The model tended to predict “average performance” too frequently, resulting in relatively low predictive accuracy overall.
This highlighted a key limitation of treating a language model purely as a text generator: it may not naturally behave like a structured prediction system.
The Qwen experiment demonstrated promising improvements through architectural customization. However, because this phase of the project focused on proving the concept rather than exhaustive optimization, the model did not yet reach the highest performance levels.
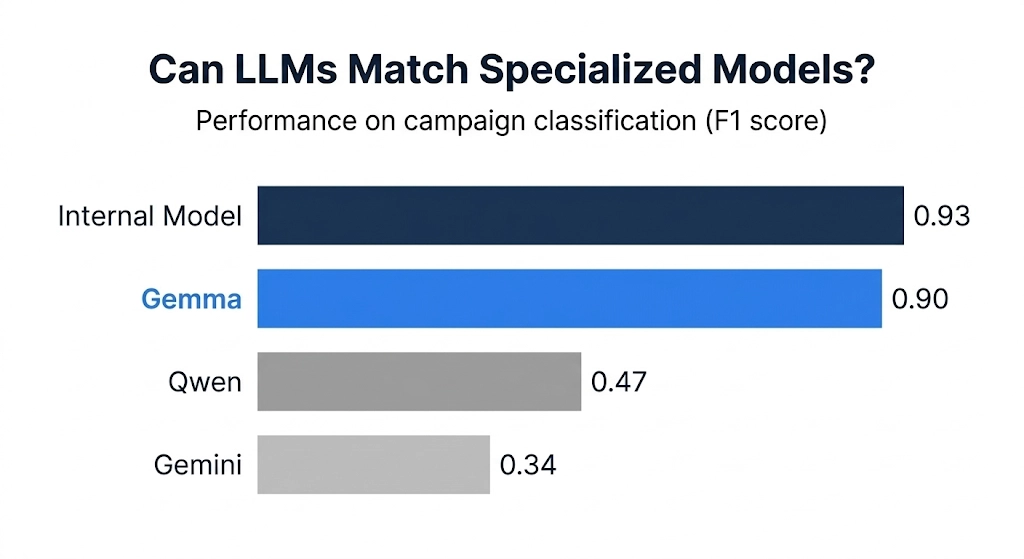
The standout performer was the fine-tuned Gemma model.
With the right training strategy and architectural adjustments, Gemma achieved prediction accuracy very close to our specialized internal machine learning system, performing strongly across all performance categories.
In other words, a modern language model—when properly configured—was able to rival a system specifically designed for the task with a ~90% F1 score, virtually matching our specialized internal model’s ~93% performance.
Why Gemma Won
The key lesson from this experiment is that success in AI depends less on the specific model and more on how it is implemented.
The managed Gemini workflow prioritized convenience and rapid deployment, but its limited customization prevented us from adapting the model’s behaviour to the nuances of our dataset.
The Qwen workflow provided maximum flexibility but required significantly more tuning and engineering to unlock its full potential.
Gemma offered the ideal balance.
It allowed enough architectural control to reshape the model into a structured prediction engine while still benefiting from robust training infrastructure.
This combination enabled the model to learn the subtle relationships that determine campaign success.
Insights Beyond Prediction
Beyond pure performance, the experiment produced valuable insights about marketing dynamics themselves.
By analysing how the best-performing model made predictions, we could identify which campaign factors had the greatest influence on outcomes.
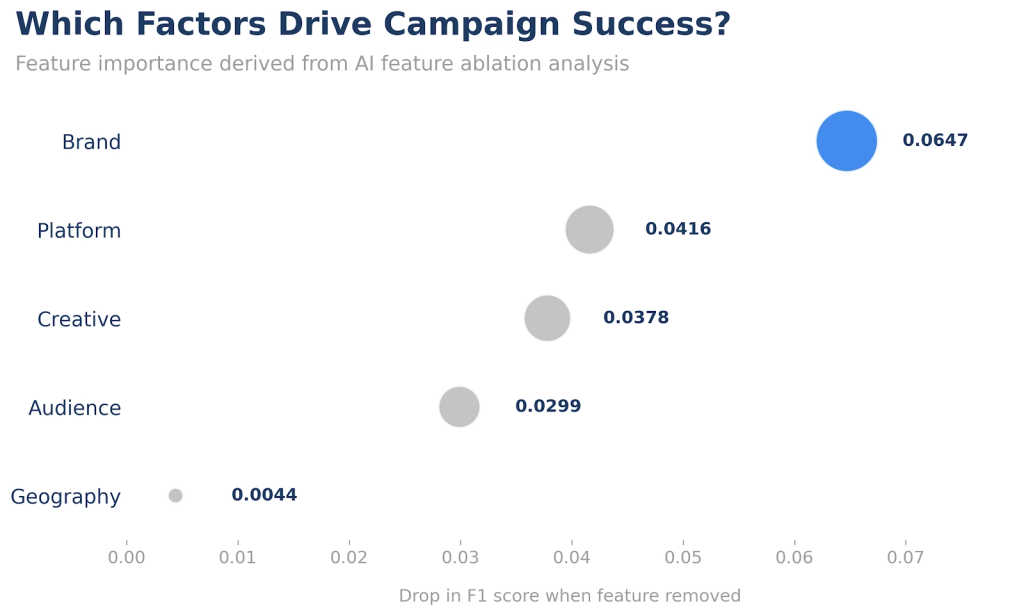
Three signals stood out consistently:
- Brand positioning
- Platform selection
- Creative messaging
These factors had a stronger influence on campaign performance than geographic targeting or audience description.
While this aligns with marketing intuition, the ability to quantify these relationships provides a powerful foundation for future decision-making.
Instead of relying solely on experience or instinct, marketers can combine creative expertise with data-driven insight.
What This Means for Businesses
For organizations exploring AI in marketing and advertising, this research carries several important implications.
First, modern language models can indeed rival specialized machine learning systems when applied correctly.
Second, the architecture surrounding the model is just as important as the model itself. Systems designed for open-ended conversation must often be adapted before they can function effectively as prediction engines.
Third, the ability to interpret narrative context opens new possibilities for marketing intelligence.
Instead of relying solely on structured datasets, organizations can analyse campaign descriptions, creative briefs, and strategic messaging to generate predictive insight.
This represents a significant shift in how marketing data can be used.
The Impact for the WPP AI Lab
For the WPP AI Lab, this experiment served several important purposes.
It demonstrated that advanced AI systems can be adapted to solve complex marketing prediction problems with performance comparable to specialized models.
It strengthened our internal capabilities in designing and deploying custom AI architectures.
And it provided a clear blueprint for future innovation.
By combining deep expertise in machine learning with a practical understanding of marketing challenges, we can build systems that help organizations make smarter decisions faster.
Looking Ahead
Artificial intelligence is evolving at an extraordinary pace.
However, the most important innovations will not come from models alone. They will emerge from how organizations integrate these technologies into real business workflows.
Our experiment showed that when applied thoughtfully, AI can move beyond hype and deliver measurable value.
It can help marketers understand their audiences more deeply, design campaigns more effectively, and allocate resources more intelligently.
Most importantly, it demonstrates that the future of marketing intelligence lies not in replacing human creativity but in augmenting it with powerful analytical tools.
The question was never whether AI would transform marketing. The real challenge is learning how to apply it in ways that truly work. And through this journey, we have taken an important step toward that future.
Disclaimer: This content was created with AI assistance. All research and conclusions are the work of the WPP AI Lab team.
Leave a Reply