
Multimodal Federated Learning for Marketing Outcome Prediction: A Deep Dive Flower-Based Simulation Analysis
Training high-capacity models for marketing prediction is often constrained not by algorithmic complexity but by data locality. In cross-portfolio settings, informative signals are dispersed across organizational silos, and raw data is typically non-transferable due to privacy, and governance restrictions. Conventional centralized training, pooling all data to train a single model, is therefore often infeasible, while standard distributed training within a single trust domain does not address the fundamental challenge of learning across independent data owners.
The Multimodal Challenge
The problem is further complicated by the inherently multimodal nature of modern marketing data. A single campaign may span visual brand assets, textual ad copy, structured audience segments, and cross-channel performance metrics. Multimodal learning, training models to reason jointly across such heterogeneous inputs, is already among the most demanding areas in machine learning. Under collaborative constraints, the challenge intensifies: clients may hold different modality combinations in varying formats and volumes, and a global model must learn from this fragmented landscape without ever accessing raw data.
Why use Federated Learning?
Federated Learning (FL) offers a principled alternative by keeping data at the edge and exchanging only model updates. In the standard cross-silo formulation, each client trains locally on its private partition, a central coordinator aggregates the resulting parameters, and the process repeats over communication rounds until convergence. This report studies that pipeline in a multimodal classification setting, where each sample is a structured composition of contextual modalities and the task is ternary outcome prediction.
The Objective
A fundamental question must be answered before committing to real-world deployment:
Does federated learning perform well enough on multimodal marketing data to justify its tradeoffs?
Centralized training retains an intrinsic advantage, full visibility into the data distribution at every optimization step. The goal of this work is not to show that FL surpasses centralized performance, but to determine whether it approximates it closely enough for the privacy and collaboration benefits to be practically worthwhile. We further examine FL robustness under realistic stress conditions: scaling the number of participating clients, introducing data noise, and investigating the complexity of relationships among different modalities. If this intersection of federated and multimodal learning can be made viable, it enables collaborative intelligence across organizations at a scale neither approach could achieve alone.
To ensure a controlled, reproducible analysis, we generate multimodal datasets with a configurable synthetic generator and assign them to virtual clients using identically independently distributed (IID)-like, homogeneous partitioning to simulate collaborative training. We implement the full FL loop in simulation mode using Flower, a state-of-the-art federated learning framework. The experiments that follow quantify how federation affects predictive quality relative to a centralized baseline, and how performance varies with (i) the number of clients, (ii) dataset noise levels, and (iii) the prioritization of cross-modal relationships in the synthetic data generation based on their frequencies.
Handling the Data
Synthetic Data Generator
For our experiments, we used proprietary multimodal synthetic datasets generated with an internally developed framework. The synthetic data was designed to replicate real-world marketing dynamics, where campaign outcomes are shaped by the interplay of multiple contextual factors (modalities). The framework provides precise control over the composition of each data instance, enabling rigorous evaluation of the proposed model under known conditions and full transparency into the factors driving campaign performance. The specific hyper parameters governing each dataset’s generation are detailed in the experimental sections below, where they are adjusted according to each experiment’s objectives.
Each campaign instance within the dataset is characterized by five distinct modalities:
- Audience – the target consumer segment,
- Brand – the strategic positioning and perceptual attributes of the brand,
- Creative – the tonal and messaging characteristics of the campaign,
- Platform – the distribution channel on which the campaign is deployed, and
- Geography – the market region(s) in which the campaign is activated.
Each sample is assigned a categorical performance label — Positive (Overperforming), Negative (Underperforming), or Average (Performing within expected bounds) — indicating the projected campaign outcome for a given multimodal configuration. This ternary classification scheme enables the model to learn discriminative representations across the full spectrum of campaign effectiveness.
Data Partitioning
After generating the training and test datasets with the synthetic data generator, the training data must be partitioned across federated clients to simulate a real-world scenario in which multiple companies collaboratively train the model, each holding its own proprietary data. In practice, this partitioning step would not be necessary, as each company would naturally possess its own local dataset. However, in our simulated environment, the codebase provides the partition-dataset script, which splits the training dataset across a user-defined number of clients using either a homogeneous or heterogeneous partitioning strategy.
Under homogeneous partitioning, the script groups training samples by label and divides each label’s indices into equal-sized segments across the specified number of clients. This ensures each client receives a statistically representative subset of the data with approximately uniform class proportions. Under heterogeneous partitioning, the script samples a Dirichlet distribution with concentration parameter alpha to determine the proportion of each class assigned to each client, producing non-IID label skew of configurable severity. Lower alpha values yield more extreme label imbalance across clients, while higher values produce distributions that progressively approach the homogeneous case. For our proof-of-concept research project, we focus our experiments on a homogeneous data split.
Upon completion, the script outputs individual training files per client, a shared server test set, and a heat map visualizing the label distribution across all partitions. An example of a homogeneous partition heat map across 5 clients is shown below:
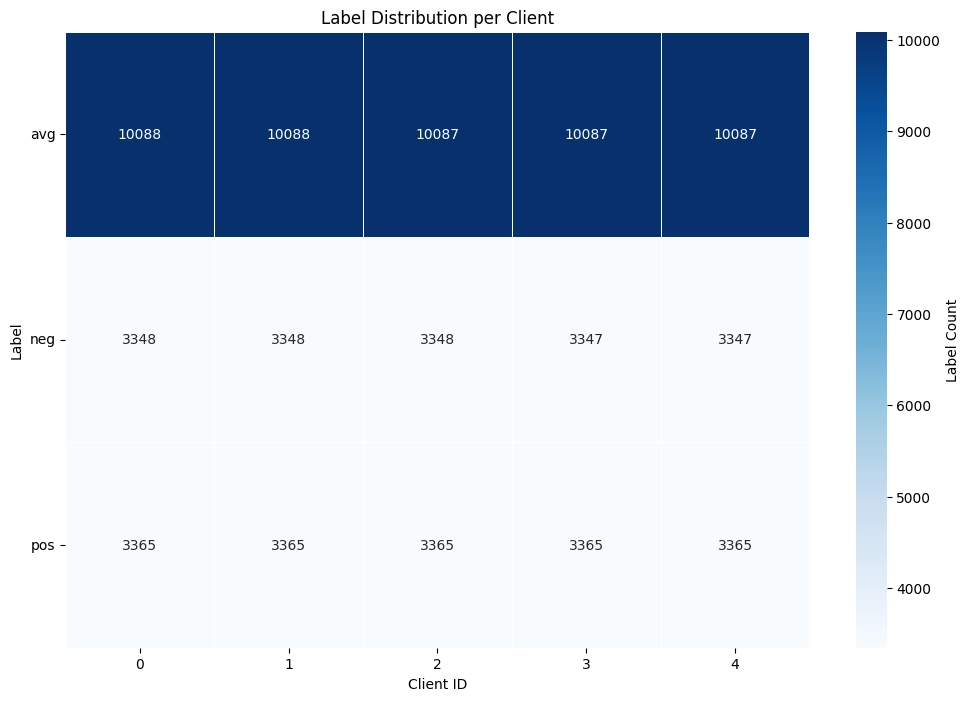
Figure 1: Heat map showing homogeneous data partitioning across 5 clients in the federated learning scenario
With the dataset now generated and partitioned into per-client training files, we can move from data preparation to the federated training setup. In the next section, we introduce Flower, the framework we use to orchestrate client selection, parameter exchange, and aggregation over these partitions.
Flower: The Federated Learning Framework
What is Flower?
Flower is an open-source, framework-agnostic federated learning framework that enables collaborative model training across decentralized data holders without requiring raw data to leave its source. It supports both real-world distributed deployment over gRPC and local simulation through a Virtual Client Engine (VCE) backed by the Ray distributed runtime. In simulation mode, clients are virtualized as ephemeral objects instantiated on demand, allowing researchers to simulate federations of arbitrary size on a single machine with fine-grained resource control.
Simulation Cycle
The simulation follows a centralized client-server architecture executed over iterative communication rounds. Each round proceeds through five sequential stages:

Figure 2: Breakdown of a federated learning communication round into steps under the Flower framework.
Each virtual client is instantiated at the beginning of its task, executes training or evaluation, returns results, and is immediately destroyed. This allows all five clients in this configuration to run concurrently without persistent memory allocation.
The above diagram illustrates a complete FL communication round orchestrated by the Flower framework. The process begins with Client Selection, where the Flower Server selects a subset of participants from a broader pool. The server then distributes the current global model parameters to all selected clients simultaneously. Each client performs Local Training in parallel using Ray workers, training on its own private dataset to produce a locally updated model. These Local Updates are sent back to the server, which performs Federated Averaging(FedAvg). This is a weighted average, so clients with more data have proportionally more influence on the updated global model. A readable way to write the FedAvg update is:
Where:
- is the updated global model parameters after aggregation.
- is the set of clients selected to participate in this round.
- is the model parameters after client finishes local training.
- is the number of training samples held by client .
- is the total number of samples across the participating clients.
Finally, a Federated Evaluation step assesses the updated global model across all clients and reports per-client accuracy metrics. This pipeline repeats across successive FL rounds until convergence.
A key architectural detail of Flower’s VirtualClientEngine underpins this workflow: each virtual client is instantiated at the start of its task, runs training or evaluation, returns results, and is immediately destroyed. This enables all clients in the configuration to run concurrently without persistent memory allocation, making the system highly scalable even on resource-constrained hardware. By keeping raw data decentralized at the edge and exchanging only model parameters, this design preserves data privacy by default while still enabling collaborative model improvement across heterogeneous environments.
Configuration Reference
The simulation is governed by a YAML configuration organized into five sections that correspond to Flower’s core components. Here, we present the YAML file with its default values.
server:
strategy: Mean
fraction_fit: 1.0
fraction_eval: 1.0
num_rounds: 4
server_dataset_included: false
client:
num_clients: 5
model:
name: GeneralisedJointModel_3cls_feat_drop
hidden_embed_dim: 256
embed_dim: 256
hidden_dim: 256
dropout_prob: 0.3
modality_dropout_prob: 0
local_epochs: 5
batch_size: 64
lr: 1e-3
weight_decay: 1e-4
optuna_n_trials: 3
general:
use_wandb: true
random_seed: 42
text_embedding_task: classification
data_version: V28_noise_0_percent
data_split: homogeneous
alpha: 0.1
one_hot_modalities:
backend:
client_resources:
num_cpus: 2.0
num_gpus: 0.0
To run an experiment, the user only needs to adjust the desired parameters in this YAML file and execute the simulation with:
poetry run simulation
The framework reads the configuration, initializes all components accordingly, and executes the full federated learning cycle without any additional setup. Below, we explain what each section’s default values represent.
Server Configuration
Defines the central orchestrator responsible for client coordination, parameter distribution, and aggregation.
| Parameter | Default Value | Description |
|---|---|---|
strategy | Mean | Aggregation strategy implementing Federated Averaging (FedAvg), where client model parameters are averaged weighted by each client’s local dataset size. |
fraction_fit | 1.0 | Fraction of clients selected for training each round. At 1.0, all clients participate in every round. |
fraction_eval | 1.0 | Fraction of clients selected for evaluation each round. At 1.0, all clients evaluate after each aggregation. |
num_rounds | 4 | Total number of federated communication rounds. Combined with 5 local epochs per round (default value), each data sample is exposed to 20 effective training epochs. |
server_dataset_included | false | The server holds no data partition and acts purely as a parameter aggregator. |
Client Configuration
Defines the federated client pool. Each client represents an independent data silo with its own private partition.
| Parameter | Default Value | Description |
|---|---|---|
num_clients | 5 | Total number of virtual clients in the federation. With full participation, this constitutes a cross-silo setting with a small number of reliable, always-available participants. |
Model Configuration
Defines the neural network architecture and the local training hyper parameters applied on each client.
Architecture Parameters
| Parameter | Default Value | Description |
|---|---|---|
name | GeneralisedJointModel_3cls_feat_drop | A custom multimodal fusion model with a modality-agnostic joint embedding space, three classification heads for multi-task prediction, and feature-level dropout regularization. |
hidden_embed_dim | 256 | Dimensionality of hidden layers within each modality-specific encoder, applied before the fusion stage. |
embed_dim | 256 | Dimensionality of the joint fused embedding space shared across all classification heads. |
hidden_dim | 256 | Dimensionality of hidden layers within each of the three classification heads. |
dropout_prob | 0.3 | Dropout probability applied in the classification heads and hidden layers. |
modality_dropout_prob | 0 | Probability of dropping entire modality branches during training. At 0, all modalities are always present (disabled). |
Training Parameters
| Parameter | Default Value | Description |
|---|---|---|
local_epochs | 5 | Number of complete passes over a client’s local dataset per communication round. |
batch_size | 64 | Mini-batch size for local stochastic gradient descent. |
lr | 1e-3 | Learning rate for the local optimizer. |
weight_decay | 1e-4 | L2 regularization coefficient penalizing large weight magnitudes. |
optuna_n_trials | 3 | Number of Optuna Bayesian hyper parameter optimization trials. |
Data Configuration
Controls dataset versioning, partitioning strategy, and modality-specific preprocessing.
| Parameter | Default Value | Description |
|---|---|---|
data_version | V28_noise_0_percent | Dataset version identifier pointing to a specific preprocessed dataset. |
data_split | homogeneous | Partitioning strategy across clients. Points to a homogeneous data distribution folder where data is split in an IID manner and each client receives a statistically representative partition with similar class distributions. The alternative heterogeneous points to a non-IID distribution folder where splits are governed by alpha. |
alpha | 0.1 | Dirichlet concentration parameter controlling non-IID severity when data_split points to a heterogeneous distribution folder. Currently inactive as the configuration uses the homogeneous split. When active, lower values produce more extreme label skew across clients. |
text_embedding_task | classification | Configures the text modality encoder for a classification objective, affecting pooling strategy and embedding optimization. |
one_hot_modalities | null | Specifies modalities requiring one-hot encoding. Currently none. |
The data_split and alpha parameters in the simulation YAML configuration must match the partitioning strategy used when running the partition-dataset script, because the simulation reads client data from the output directory, whose folder name encodes both the split type and the number of clients.
Simulation Backend & Experiment Management
Controls reproducibility, logging, and resource allocation for parallel execution of virtual clients through the Ray runtime.
| Parameter | Default Value | Description |
|---|---|---|
use_wandb | true | Enables Weights & Biases experiment tracking for real-time metric logging and cross-experiment comparison. |
random_seed | 42 | Global seed ensuring reproducibility in our experiments. |
num_cpus | 2.0 | CPU cores reserved per virtual client task. Ray schedules a client only when the required cores are available. |
num_gpus | 0.0 | GPU allocation per client. At 0.0, all computation runs on CPU and concurrency is bounded solely by CPU availability. |
Experiments
The following section outlines three experiments that compare federated learning with centralized training under different conditions.
- Experiment 1 establishes a baseline comparison and tests how FL performance changes as the number of clients increases.
- Experiment 2 examines how robust both approaches are when controlled noise is added to the training data.
- Experiment 3 evaluates whether emphasizing common vs. rare cross-modal relationships during synthetic data generation affects model performance.
Overall, these experiments measure both the absolute performance of each approach and whether the performance gap between centralized and federated training remains consistent as the setting becomes more challenging.
To ensure a fair comparative evaluation, all experimental variables were held constant across centralized and federated configurations. Both setups employ an identical model architecture, ensuring that any observed performance differences are attributable solely to the training paradigm rather than structural variations in the model itself.
The total computational training budget was also standardized: the centralized model undergoes 20 sequential training epochs, while the federated configuration distributes this across 4 global communication rounds with each client performing 5 local epochs per round, yielding an equivalent total of 20 epochs. Furthermore, the training data is partitioned uniformly across all participating clients under a homogeneous assumption, ensuring that each client’s local dataset is a representative subset of the global distribution. This controlled partitioning ensures that any performance degradation observed with increasing client counts can be attributed to the effects of federation and aggregation at scale, rather than to statistical heterogeneity across client data.
Experiment 1: Centralized vs. Federated Performance
The Data
We employed the V16 synthetic dataset, generated using the synthetic data generator, comprising 84K training samples and 36K test samples. For both centralized and federated training configurations, raw input features — specifically Audience, Brand, Creative, Platform, and Geography — were encoded into dense representations using Vertex AI embeddings as a preprocessing step.
The Results
| Training Configuration | Score | Negative F1 | Positive F1 | Average F1 |
|---|---|---|---|---|
| Centralized (Baseline) | 0.7967 | 0.7074 | 0.7305 | 0.9523 |
| FL with 5 clients | 0.7623 | 0.6841 | 0.6571 | 0.9458 |
| FL with 10 clients | 0.7029 | 0.5781 | 0.5902 | 0.9405 |
| FL with 15 clients | 0.6765 | 0.5345 | 0.5581 | 0.9368 |
The centralized training configuration establishes the upper performance bound at a score of 0.7967. This outcome is theoretically expected, as the model benefits from unrestricted access to the complete dataset, without information loss due to partitioning or coordination overhead inherent in distributed paradigms. It therefore serves as the reference benchmark for all federated configurations.
The federated learning results reveal a consistent and monotonic degradation in performance as the number of participating clients increases. With 5 clients, the model achieves a score of 0.7623 — a modest decline of approximately 3.5 points from the centralized baseline. However, scaling to 10 and 15 clients yields more substantial reductions to 0.7029 and 0.6765, respectively. This pattern is uniformly reflected across all evaluation metrics; however, the decline is most pronounced in the Negative F1 and Positive F1 scores, which degrade at a markedly steeper rate than Average F1. This suggests that class-specific discriminative performance is more sensitive to data partitioning than overall classification ability.
This observed degradation is primarily attributable to the aggregation penalty. As the number of clients grows, the training corpus is divided into progressively smaller subsets, resulting in local model updates that are less representative of the global data distribution. The increased variance among these updates introduces noise during server-side aggregation, impeding convergence toward a robust global model.
Lesson Learned: FL with 5 clients comes remarkably close to centralized performance, showing that federated collaboration is viable with minimal accuracy loss. However, as the number of clients grows, makes it progressively harder for the global model to match centralized results.
Experiment 2: Resilience to Noisy Data
The Data
To conduct this experiment, it was necessary to generate synthetic data with controlled levels of noise. To understand what noise means in this context, it is important to first describe how the synthetic data is generated.
The data generation process is grounded in a predefined graph structure. In this graph, nodes represent distinct values for each modality — namely Audience, Brand, Creative, Platform, and Geography — while edges encode the pairwise relationships between these values. Each edge carries a label of either Positive (indicating an over performing campaign) or Negative (indicating an underperforming campaign).
The generator samples from this graph to produce a user-defined number of data points, subject to a set of hard constraints governed by configurable hyper parameters. Specifically, the user defines the desired number of samples for each target label: Positive, Negative, and Average. The generation of a single data sample proceeds as follows:
- Value Selection: One or more unique values are selected for each modality.
- Pairwise Evaluation: All pairwise combinations among the selected values are evaluated against the graph. Each combination is classified as positive, negative, or missing — the latter indicating that no edge exists between the two values in the graph.
- Proportion Calculation: The proportions of positive, negative, and missing combinations are computed relative to the total number of pairwise combinations.
- Label Assignment: These proportions are then compared against predefined acceptable ranges specified in the hyper parameters for each target label. If the proportions fall within the range defined for Positive, Negative, or Average, the sample is assigned the corresponding label. If the proportions do not satisfy any of the defined ranges, the sample is discarded and the generation process is repeated.
A key question that arises from this process is: How are the predefined acceptable ranges for each target label determined?
To address this, we conducted the following preliminary experiment. We randomly sampled 10,000 subgraphs, each comprising 1,000 edges, from the initial graph. For each subgraph, we computed the proportions of positive, negative, and missing pairwise combinations. From these 10,000 samples, we derived the mean and standard deviation among Positive, Negative, and Missing values. These statistics were then used to define the acceptable range for the Average target label, representing the typical composition of a randomly sampled subgraph.
The acceptable ranges for the Positive and Negative target labels were subsequently defined by shifting the boundaries of the Average range along the respective axes. Specifically, the Positive range requires the proportion of positive combinations to exceed the Average upper bound by at least 5 standard deviations, and similarly, the Negative range requires the proportion of negative combinations to exceed the Average upper bound by the same margin. This ensures a clear statistical separation between the three label categories, such that samples assigned to the Positive or Negative class exhibit meaningfully distinct distributional characteristics from those labeled as Average.
Based on the above methodology, we established the appropriate acceptable ranges for each target label. This, however, raises a subsequent question: What constitutes noise in this context?
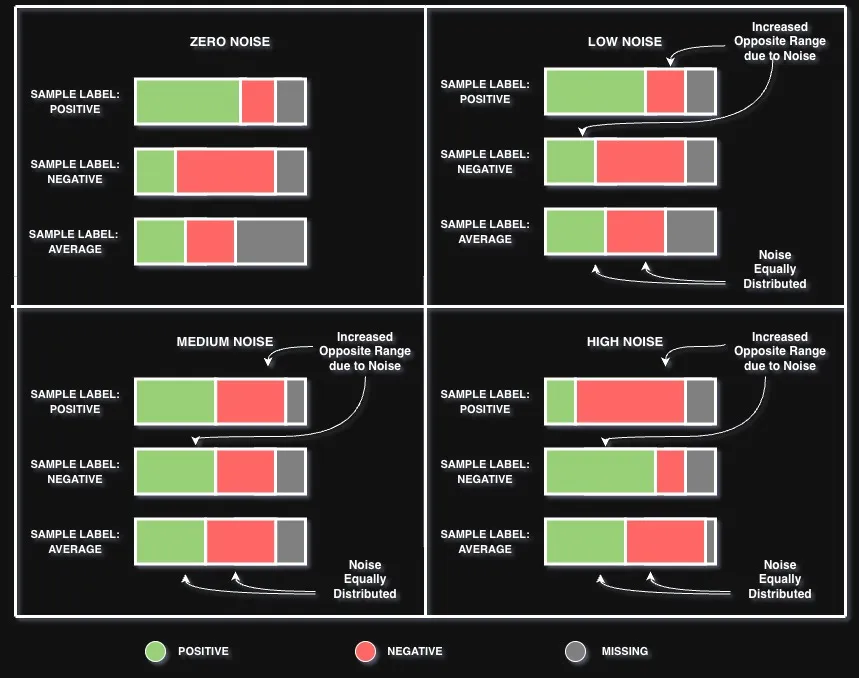
Figure 3: Impact of additive noise on the acceptable ranges for each target label in the synthetic data generator. As noise increases from zero to high, the opposing acceptable range for each sample’s target label progressively widens. This increases the acceptable proportion of negative combinations for the Positive label, positive combinations for the Negative label, and both equally for the Average label, thereby reducing the distributional separation between label categories.
In our framework, noise is defined as the relaxation of the opposing acceptable range for a given target label. Specifically, introducing noise to the Positive target label corresponds to increasing its acceptable proportion of negative combinations — effectively reducing the degree of “positiveness” required for a sample to be classified as Positive. Conversely, adding noise to the Negative target label increases its acceptable proportion of positive combinations. For the Average target label, the additive noise is distributed equally across both the Positive and Negative acceptable ranges.
This noise mechanism is applied at three levels of intervention — low, medium, and high — each progressively widening the acceptable range of the opposing value for a given target label. The figure above illustrates how the acceptable ranges for each target label are impacted under each level of intervention.
To support this experiment, four synthetic datasets were generated, each comprising 84K training samples and 36K test samples:
- Clean: No noise intervention applied.
- Low Noise: Low-level relaxation of the opposing acceptable ranges.
- Medium Noise: Medium-level relaxation of the opposing acceptable ranges.
- High Noise: High-level relaxation of the opposing acceptable ranges.
The federated learning simulation was configured with five participating clients, and performance was evaluated against the centralized baseline across all four dataset conditions.
The Results
| Training Configuration | Score | Negative F1 | Average F1 | Positive F1 |
|---|---|---|---|---|
| FL with no noise | 0.8074 | 0.8029 | 0.8633 | 0.7559 |
| Centralized with no noise | 0.8205 | 0.8165 | 0.8692 | 0.7760 |
| FL with low noise | 0.7923 | 0.7902 | 0.8555 | 0.7313 |
| Centralized with low noise | 0.8159 | 0.8039 | 0.8750 | 0.7686 |
| FL with medium noise | 0.7826 | 0.7718 | 0.8570 | 0.7189 |
| Centralized with medium noise | 0.8017 | 0.7876 | 0.8643 | 0.7533 |
| FL with high noise | 0.7609 | 0.7344 | 0.8625 | 0.6859 |
| Centralized with high noise | 0.7811 | 0.7551 | 0.8659 | 0.7221 |
As anticipated, both the centralized and federated models achieve their highest performance on clean data and exhibit a gradual decline as noise levels increase. At the highest noise intervention, the centralized model’s score decreases from 0.8205 to 0.7811, while the federated model’s score declines from 0.8074 to 0.7609 — representing drops of approximately 3.9 and 4.7 percentage points, respectively.
Notably, neither model exhibits catastrophic degradation under any noise condition. Even at the highest level of intervention, both configurations maintain reasonable performance. The most pronounced declines are observed in the Positive F1 and Negative F1 scores, which is consistent with the noise injection methodology described above: since noise is introduced by relaxing the opposing acceptable range for each target label, the boundaries between Positive and Negative classes become increasingly blurred, making these the most challenging distinctions for the model. In contrast, the Average F1 remains remarkably stable across all noise levels for both configurations, indicating that the models’ capacity to capture general distributional patterns is largely unaffected by the introduced noise.
Consistent with the findings from Experiment 1, the centralized model maintains a performance advantage over the federated configuration at every noise level. However, the magnitude of this gap remains approximately constant across all noise conditions. This observation is significant: it indicates that the federated setup does not exhibit increased sensitivity to noisy data relative to its centralized counterpart. The performance differential between the two paradigms is attributable to the aggregation penalty discussed in Experiment 1, rather than to any compounding effect of noise on the federated training process.
Lesson Learned: Real-world data is inherently noisy, and any viable model must be able to handle that. Both centralized and FL models show strong resilience, performance declines gradually rather than breaking down, even when the data is heavily corrupted. Importantly, FL’s relative performance holds steady across noise levels, suggesting it is no more vulnerable to messy data than centralized training.
Experiment 3: Impact of Cross-Modal Relationships under Synthetic Data Generation
The Data
Leveraging the synthetic data generator enables the investigation of additional structural characteristics of the initial marketing graph — specifically, the edge types representing pairwise relationships between modalities. Understanding which modality pairs (e.g., Audience–Brand or Creative–Geography) are most influential on model performance is of particular interest.
To this end, we conducted a preliminary analysis: 10,000 subgraphs, each comprising 1,000 edges, were sampled from the initial multimodal graph, and the mean and standard deviation of the observed edge-type frequencies were computed. The table below presents the modality relationships ranked by frequency, from the most common to the most rare.
| Modality Relationship | Mean Frequency |
|---|---|
| Brand to Content | 8.48 |
| Audience to Content | 7.29 |
| Content to Geography | 6.57 |
| Audience to Brand | 5.90 |
| Audience to Geography | 5.84 |
| Brand to Geography | 5.55 |
| Content to Content | 3.24 |
| Brand to Brand | 3.18 |
| Content to Platform | 1.88 |
| Brand to Platform | 1.52 |
| Audience to Audience | 1.18 |
| Audience to Platform | 1.16 |
This frequency distribution informed the design of a subsequent performance-based experiment. The synthetic data generator exposes two relevant hyper parameters: a high pair preference, which increases the likelihood of sampling edges from the specified modality relationships, and a low pair preference, which suppresses them. Using these controls, three synthetic datasets were generated under distinct configurations:
- Common First: The two highest-frequency modality relationships are assigned as the high pair, and the two lowest-frequency relationships as the low pair.
- Rare First: The inverse configuration, where the two lowest-frequency relationships are assigned as the high pair and the two highest as the low pair.
- Middle Ground: The four middle-ranked relationships from the frequency table are assigned to the high and low pairs accordingly.
All remaining hyper parameters were held constant across the three configurations: noise levels were set to zero, and the federated learning simulation was conducted with five participating clients, consistent with the setup described in prior experiments. The training size remains 84k, as the test size is equal to 36K.
The Results
| Training Configuration | Score | Negative F1 | Average F1 | Positive F1 |
|---|---|---|---|---|
| Centralized Common First | 0.8803 | 0.8856 | 0.9245 | 0.8308 |
| FL Common First | 0.8748 | 0.8775 | 0.9150 | 0.8320 |
| Centralized Rare First | 0.9441 | 0.9503 | 0.9579 | 0.9242 |
| FL Rare First | 0.9343 | 0.9470 | 0.9505 | 0.9054 |
| Centralized Middle Ground | 0.8813 | 0.8744 | 0.9143 | 0.8551 |
| FL Middle Ground | 0.8625 | 0.8677 | 0.9009 | 0.8188 |
The results reveal a notable disparity in performance across the three dataset configurations. The Rare First configuration substantially outperforms the other two, achieving scores of 0.9441 (Centralized) and 0.9343 (FL) — a margin of approximately 6–8 percentage points over the Common First and Middle Ground configurations, which yield scores in the 0.86–0.88 range. This performance advantage is consistently reflected across all evaluation metrics, with particularly pronounced gains in Positive F1, where the Rare First configuration achieves 0.9242 (Centralized) and 0.9054 (FL), compared to values in the 0.81–0.85 range for the alternative configurations.
This finding is counterintuitive yet theoretically interpretable. Frequently occurring modality combinations, by virtue of their prevalence, contribute comparatively less discriminative information to the learning process — the decision boundaries they define are, in effect, already well-represented and easily separable. In contrast, rare combinations compel the model to learn more nuanced and distinctive feature interactions, resulting in richer decision boundaries between Positive and Negative campaign outcomes. The learning signal provided by atypical patterns is therefore disproportionately more informative per sample.
Consistent with findings from prior experiments, the centralized model maintains a modest performance advantage over the federated configuration across all three dataset strategies. Crucially, however, the relative ranking of dataset configurations remains identical under both training paradigms: Rare First consistently outperforms Common First and Middle Ground, regardless of whether training is conducted centrally or in a federated manner.
Lesson Learned: Not all data is equally valuable. Prioritizing on rare, atypical feature combinations produces significantly better models than focusing mostly on common patterns. This has direct implications for how we design synthetic datasets: rather than mimicking the most typical marketing dynamics, we should deliberately include uncommon combinations to give the model a richer and more discriminative learning signal.
Impact and Future Directions
This work represents an initial investigation into the viability of federated learning within our operational context. The finding that centralized model performance degrades only marginally under a reasonable number of participating clients opens a promising avenue for delivering machine learning solutions that address shared industry challenges among organizations reluctant to pool their data. The federated learning paradigm enables multiple entities to collaboratively train a shared global model on their respective proprietary datasets, without exposing raw data at any stage of the training process, thereby mitigating the risk of data leakage.
Although Federated Learning has been an established collaborative learning paradigm since its introduction in 2017, it remains a highly active area of research in academia and a strategic priority for industrial adoption. The findings from WPP Lab’s initial FL research establish the foundation for continued exploration, with future work organized around the following directions:
1. Privacy Guarantees in Adversarial Federated Environments
While FL provides a relatively secure framework for multi-organizational model training, a fundamental concern persists: to what extent can the exchange of local and global model updates during each communication round be considered safe? A substantial body of literature has demonstrated that FL networks are susceptible to a range of adversarial attacks, originating from either malicious clients or a compromised central server. Addressing this vulnerability necessitates the development of robust defense mechanisms that enable honest participants to verify the integrity and trustworthiness of the collaborative learning process.
2. Evaluation Under Advanced and Realistic Federated Scenarios
While simulating collaborative training with uniformly distributed data provides a valuable baseline for foundational FL research, it does not fully capture the complexities inherent in real-world deployments. Future work will extend our preliminary investigations into data heterogeneity, building upon the noise-injection experiments conducted on synthetic datasets in this study. Additionally, we intend to evaluate the efficacy of maintaining a shared synthetic dataset on the central server as a reference benchmark for assessing the integrity of incoming model updates and detecting potentially malicious contributions. Finally, we plan to transition from the simulated FL environment currently facilitated by the Flower framework to a fully distributed architecture. By deploying distinct computational nodes to represent separate organizational entities, we aim to empirically investigate and address the communication bottlenecks inherent in practical federated deployments.
Disclaimer: This content was created with AI assistance. All research and conclusions are the work of the WPP AI Lab team.