Why Federated Learning Now?
In marketing, data is a competitive edge. The more audience signals, campaign performance data, and consumer behavior a Machine Learning (ML) model can learn from, the sharper its predictions and the greater its business impact. Across the marketing ecosystem — spanning WPP’s agencies, their clients, and external partners — the collective wealth of consumer and brand data is enormous. The potential to train models across these combined assets could unlock transformative capabilities: better audience targeting, smarter media spend, and faster creative optimization at a global scale.
But here’s the challenge. While WPP maintains centralized access to its own internal data assets, much of the most valuable complementary data resides with clients and partners and, for good reasons, it can never leave their walls. Client contracts, privacy regulations like GDPR, and the sheer sensitivity of consumer-level data make cross-organizational data pooling a non-starter. The result? Models are trained without the full picture, and transformative insights that could emerge from combining datasets across organizational boundaries remain permanently out of reach.
The traditional solution, centralized ML, pools raw data from multiple sources into a single cloud to train a global model. But uploading terabytes of sensitive data to a central server creates severe network latency and exposes collaborators to data breaches and potential violations of privacy regulations.
Distributed ML methods attempted to address this by splitting training across local worker nodes. While this reduces latency and avoids centralizing raw data, these architectures were designed for internal computing clusters, not secure collaboration between independent companies. Without cross-organization coordination, models remain isolated, difficult to align, and impossible to improve as a unified whole.
Problem: The Collaboration vs. Privacy Bottleneck
Organizations are effectively trapped between two undesirable choices: compromise sensitive data through centralization, or settle for underperforming, isolated models through distribution. Neither architecture allows multiple companies to collaboratively train a shared, high-performing model while keeping private data strictly localized.
Federated Learning (FL) offers a way out of this dilemma by bringing the model to the data, rather than the other way around. To understand why this shift matters, let’s look at how FL actually works under the hood.
How Federated Learning Works
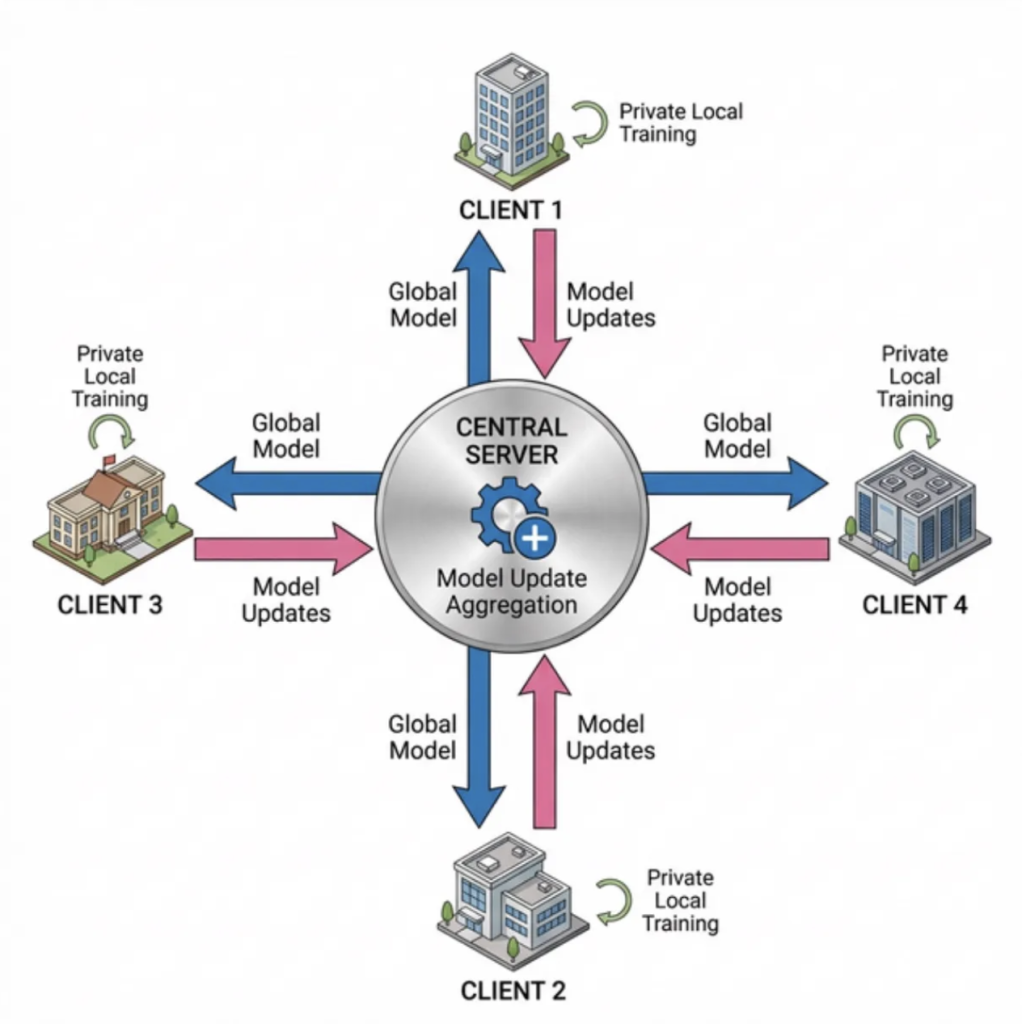
Figure 1: Overview of the Federated Learning communication cycle between a central node and distributed client nodes.
Federated Learning (FL) enables multiple organizations to collaboratively train a shared model without ever centralizing raw data. Instead of moving data to the model, FL brings the model to the data. Training proceeds through iterative rounds:
- A central server sends the current global model to all participating clients (Blue arrow).
- Each client trains the model locally on its own private data (Green arrow).
- Clients send back only their model updates, never the underlying data (Pink arrow).
- The server aggregates these updates into an improved global model and starts the next round.
Throughout this process, raw data never leaves its source. Only learned model representations are exchanged across the network.
The Multimodal Challenge
While the above privacy-preserving framework is valuable in its own right, modern marketing data adds another layer of complexity. Organizations do not just work with spreadsheets and numbers. They work with images, video, text, audio, and structured data, often all at once. A single campaign might involve visual brand assets, ad copy, audience segments, and performance metrics across channels. Training models that can reason across these different data types, known as multimodal learning, is already one of the most demanding challenges in ML.
Now combine that with the constraints of federated learning. Each client may hold different combinations of modalities, in different formats and volumes. One partner might contribute rich visual data, another mostly text and tabular records. Coordinating a single global model that learns effectively from this fragmented, heterogeneous landscape, without ever seeing the raw data, pushes the problem to a new level of complexity.
This is precisely what makes the intersection of FL and multimodal learning so important, and so hard. If it can be made to work, it unlocks collaborative intelligence across organizations at a scale that neither approach could achieve alone.
Our Objective: Can Federated Learning Deliver?
The promise of FL is compelling, but before investing in real-world deployment, we need to answer a fundamental question:
Does federated learning actually work well enough on multimodal marketing data to justify the tradeoff?
Centralized training will always have an inherent advantage, it sees all the data at once. The question is not whether FL can beat centralized performance, but whether it can get close enough to make the privacy and collaboration benefits worthwhile. And beyond raw performance, we need to understand how FL behaves under realistic stress conditions: more partners joining, noisy data, and complex cross-modal relationships.
To answer this, we designed a series of experiments around four key questions:
Experiment 1 — Centralized vs. Federated Performance
- How close can FL get to centralized performance? In a centralized setup, the model sees all the data at once, the ideal scenario for learning. FL, by design, fragments this data across clients. The first question is whether this tradeoff costs us meaningful accuracy, or whether FL can match centralized results despite never accessing the full dataset.
- What happens as more clients join? In practice, a federated network might involve a handful of partners or dozens. As the number of participants grows, each client holds a smaller, potentially less representative slice of the overall data. We tested how model performance scales as we increase the number of clients.
Experiment 2 — Resilience to Noisy Data
- How robust are centralized and federated models to noisy data? Real-world datasets are messy, labels can be wrongly defined, and data quality varies across partners. We deliberately introduced noise into the multimodal dataset to simulate these imperfections and measure how much degradation the model can tolerate before performance breaks down.
Experiment 3 — Cross-Modal Relationships
- How sensitive centralized and federated models to underlying cross-modal patterns? Multimodal models learn by connections between different types of data. For example, a luxury brand might target a high-income audience through a premium creative tone on a specific platform. Some of these connections appear frequently in the data, while others are rare. We tested whether emphasizing the most frequent cross-modal patterns in our synthetic data improves performance compared to emphasizing the least frequent ones, helping us understand how much the model benefits from common, naturally occurring relationships versus rare, atypical ones.
The Data
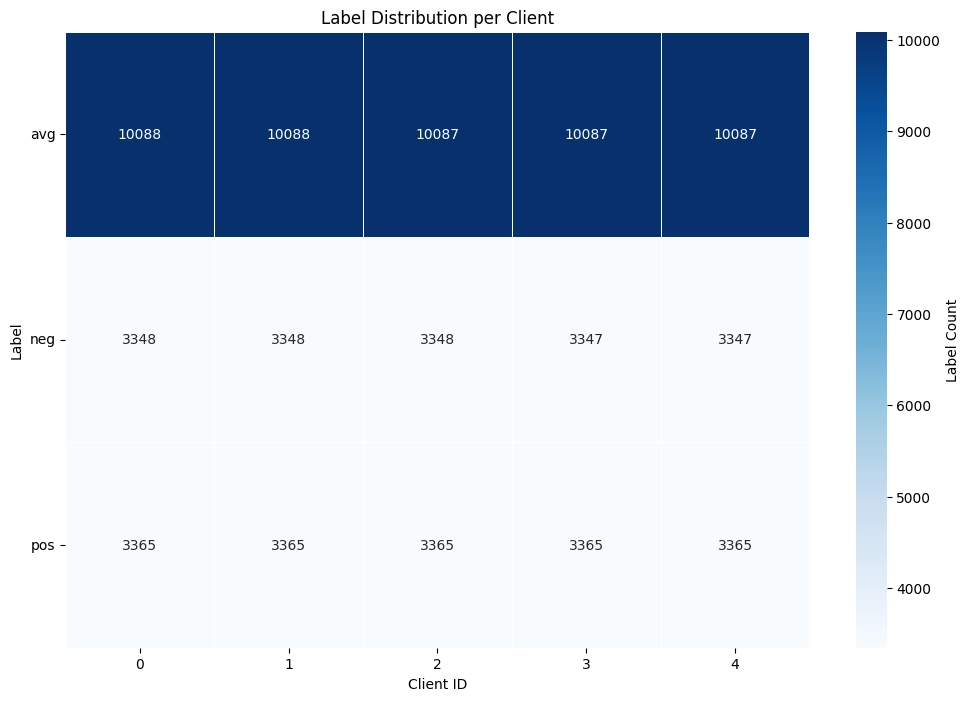
For our experiments, we used a multimodal synthetic dataset generated by our own well-tested synthetic data generator, designed to mirror real-world marketing dynamics. The generator allows us to customize various elements of the data and design targeted datasets that stress-test our model architecture under controlled conditions, giving us full visibility into the factors that drive campaign performance.
Each campaign in the dataset is described using five key modalities:
- Audience – the consumer segment being targeted
- Brand – the positioning and perception of the brand
- Creative – the tone and message of the campaign
- Platform – where the campaign runs
- Geography – the markets being targeted
Each dataset’s sample is assigned a target label, Positive (Over performing), Negative (Under performing), or Average (Average performance), indicating whether that particular combination of modalities would lead to a successful, underperforming, or average campaign outcome.
Experimental Results
All federated experiments are implemented using Flower, a widely adopted open-source framework for federated learning research and deployment. Flower allows us to simulate multi-client federated setups in a controlled environment, making it possible to rigorously test different configurations before moving to a fully distributed architecture.
To ensure a fair comparison between centralized and federated setups, we kept the playing field level. Both setups use the exact same model architecture, so any performance differences come from how the model is trained, not what is being trained. In the federated setup, data is split equally across clients so that each partner sees a representative sample. This way, when we increase the number of clients, any change in performance can be attributed to the scaling itself, not to differences in what each client’s data looks like.
Experiment 1
Question: How does FL performance compare to centralized training? What happens as more clients join?
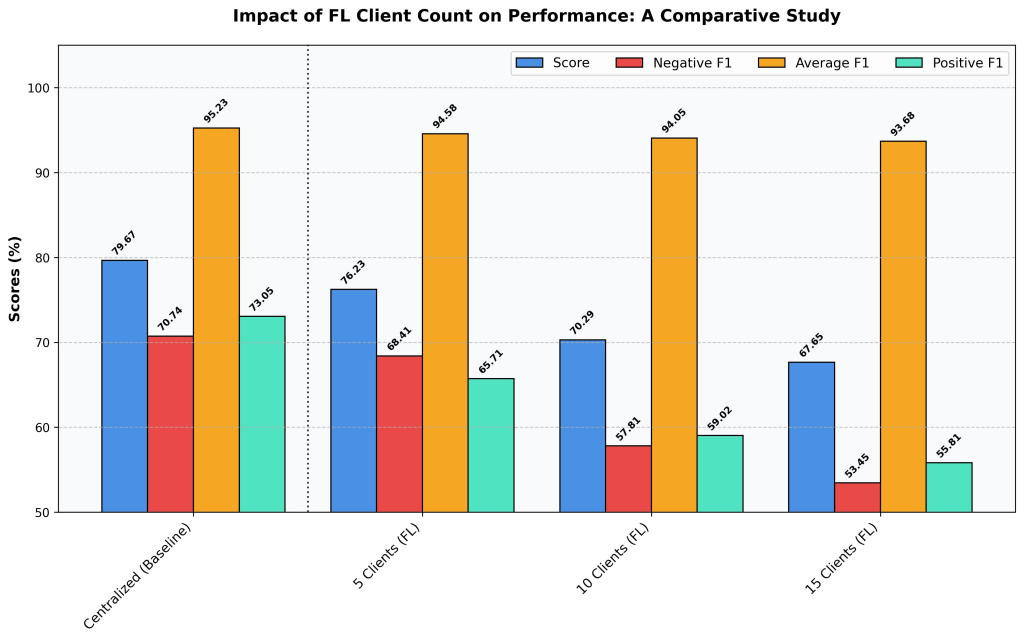
Figure 2: Impact of increasing client fragmentation on Federated Learning performance. Performance clearly degrade as the number of clients increases from 5 to 15, compared to the baseline centralized model version.
The centralized model sets the performance ceiling at 79.67%. This is expected, when a single model has direct access to all the data at once, it has the best possible conditions to learn. No information is lost to partitioning, and no coordination overhead is introduced. It’s the ideal scenario, and the benchmark everything else is measured against.
The federated results tell a clear story: as we add more clients, performance gradually declines. With 5 clients, the model reaches 76.23%, a modest drop from the centralized baseline. But as we scale to 10 and then 15 clients, scores fall to 70.29% and 67.65% respectively. The same pattern holds across all metrics, with the sharpest drops in the model’s ability to correctly identify both positive and negative cases.
Why does this happen? As more clients join, the total dataset gets divided into smaller slices. Each client sees less data, which means each client’s local training produces a less reliable picture of the overall patterns. When the server combines these local updates, the differences between them make it harder to converge on a strong global model, an effect we call the “aggregation penalty.”
Lesson Learned: FL with 5 clients comes remarkably close to centralized performance, showing that federated collaboration is viable with minimal accuracy loss. However, as the number of clients grows, makes it progressively harder for the global model to match centralized results.
Experiment 2
Question: How robust are centralized and federated models to noisy data?
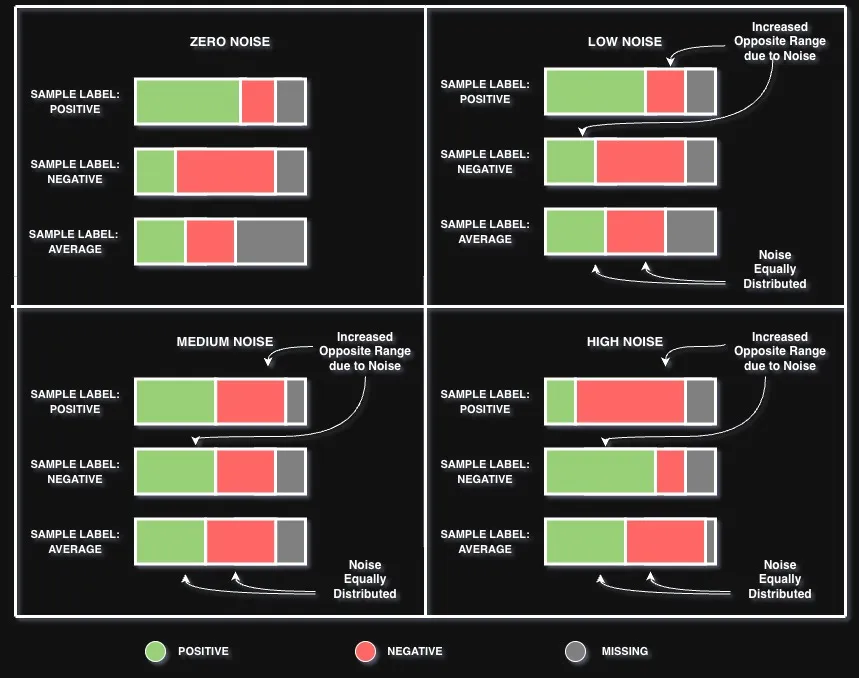
In practice, marketing data is never perfectly clean. Campaign outcomes don’t fall neatly into “this worked” or “this didn’t.” Was a campaign that slightly exceeded expectations truly a success, or just average? Was a modest underperformance a failure, or noise in the measurement? Different teams may label the same outcome differently, tracking systems introduce inconsistencies, and the line between a “positive” and “average” campaign is often blurry.
To simulate this reality, we deliberately introduced noise into our synthetic dataset by blurring the boundaries between performance classes. With no noise, the labels are clean — positive, negative, and neutral outcomes are clearly separated. As we increase the noise level from low, to medium, and then to high, the boundaries between these classes increasingly overlap, making it harder for the model to tell them apart. Think of it like gradually turning up the fog: the underlying patterns are still there, but they become harder to see. The federated learning simulation for this experiment was configured with 5 participating clients, consistent with the best-performing federated setup identified in Experiment 1.
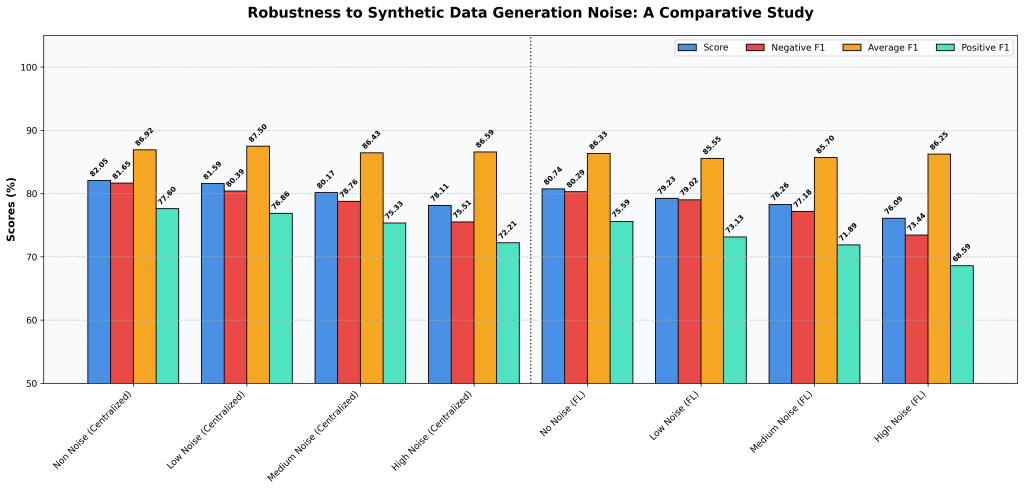
Figure 3: Performance comparison of centralized (left) and federated learning (right) configurations across increasing noise levels. Both paradigms degrade gradually, with Positive F1 and Negative F1 most affected, while the performance gap between the two remains approximately constant across all conditions.
As expected, both models perform best on clean data and gradually decline as noise increases. At high noise:
- The centralized model’s score drops from 82.05% to 78.11%
- The FL model’s score drops from 80.74% to 76.09%
The good news: neither model collapses. Even at the highest noise level both models still perform reasonably well. The overall accuracy dips, and the models struggle most with distinguishing clearly positive or clearly negative campaigns, which makes sense, since those are exactly the boundaries we blurred. However, their ability to capture general patterns across the dataset remains stable throughout.
As in Experiment 1, the centralized model maintains a consistent edge over the federated setup at every noise level, but the gap between them stays roughly the same. This means that FL doesn’t become more fragile in noisy conditions; it handles data messiness about as well as its centralized counterpart.
Lesson Learned: Real-world data is inherently noisy, and any viable model must be able to handle that. Both centralized and FL models show strong resilience — performance declines gradually rather than breaking down, even when the data is heavily corrupted. Importantly, FL’s relative performance holds steady across noise levels, suggesting it is no more vulnerable to messy data than centralized training.
Experiment 3:
Question: How sensitive centralized and federated models to underlying cross-modal patterns?
Our synthetic data generator creates campaign data based on a graph of relationships between five key factors: Audience, Brand, Creative, Platform, and Geography. Each relationship captures whether a particular combination of these factors tends to drive strong or weak campaign performance. Some of these relationships are common and obvious — they show up frequently and reflect well-known marketing dynamics. Others are rare and subtle — unusual combinations that don’t appear often but may carry uniquely valuable signal about what makes a campaign succeed or fail.
Understanding how these different types of patterns affect learning is important for both training paradigms. If the nature of the underlying data patterns matters, we need to know whether centralized and federated models respond to them in the same way — or whether one setup handles certain patterns better than the other. To investigate this, we generated three versions of our dataset, keeping everything else the same:
- Common-first: The generator focuses on the most frequently occurring combinations and downplays the rarest ones. This gives us a dataset dominated by typical, familiar marketing patterns.
- Rare-first: The opposite — the generator prioritizes the rarest combinations and downplays the most common. This fills the dataset with unusual, less obvious patterns.
- Middle-ground: The generator focuses on combinations that fall in the middle of the frequency spectrum, neither the most common nor the rarest.
As in Experiment 2, the federated learning simulation was run with 5 participating clients, and performance was compared against the centralized baseline across all three dataset versions.
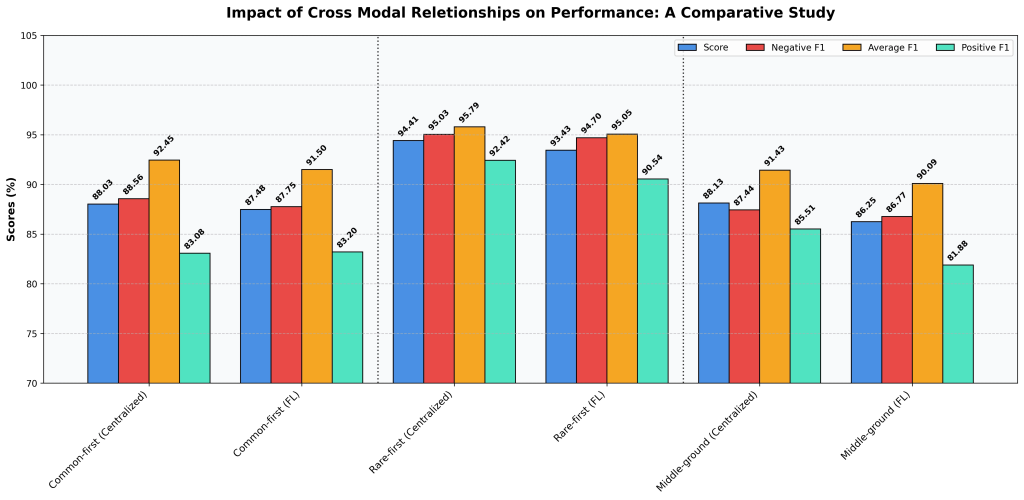
Figure 4: Impact of cross-modal relationships on model performance. Prioritizing rare feature combinations (Rare-first) substantially improves accuracy compared with focusing on common patterns, showing that atypical relationships provide a stronger learning signal for both centralized and federated learning paradigms.
The results were striking. The Rare-first configuration dramatically outperformed the other two, achieving peak scores of 94.41% (Centralized) and 93.43% (FL), compared to scores in the 86–88% range for the Common-first and Middle-ground setups.
This tells us something counterintuitive: the model learns far more from unusual feature combinations than from common ones. The typical, frequently seen patterns are in some sense “easy”, they don’t give the model much new information. But rare combinations force the model to learn more nuanced and distinctive boundaries between what makes a campaign succeed or fail.
As in previous experiments, the centralized model maintains a small edge over FL, but the ranking between dataset strategies stays the same in both setups. Whether training centrally or federally, prioritizing rare patterns is the winning strategy.
Lesson Learned: Not all data is equally valuable. Prioritizing on rare, atypical feature combinations produces significantly better models than focusing mostly on common patterns. This has direct implications for how we design synthetic datasets: rather than mimicking the most typical marketing dynamics, we should deliberately include uncommon combinations to give the model a richer and more discriminative learning signal.
The Impact and Looking ahead
This work is just the initial spark for our federated learning efforts. Verifying that the centralized ML model performance our company provides is slightly degraded under a reasonable number of users opens the discussion about delivering ML solutions that address shared challenges among clients who are reluctant to share data to tackle a common industry problem. The FL approach allows companies to securely train a shared global model on their own datasets without the risk of data leakage throughout the training process.
Although Federated Learning has been an established collaborative learning method since 2017, it remains a highly active research domain in academia and a strategic priority for industrial implementation. The findings from WPP Lab’s initial FL research establish the foundation for further exploration, specifically focusing on the following directions:
1. Privacy Constraints in Malicious FL Environments
While FL provides a relatively secure framework for multiple organizations to collaboratively train a global model, a critical question remains: how safe is it to exchange local and global model updates during each communication round? Extensive literature shows that FL networks are vulnerable to attacks from malicious clients or a compromised central server. Consequently, there is a pressing need for robust defense mechanisms that enable honest participants to verify the integrity and security of the collaborative learning process.
2. Evaluation of Advanced and Realistic FL Scenarios
While simulating collaborative training with evenly distributed data provides a valuable baseline for foundational FL research, it does not fully capture the complexities of real-world implementations. Our next objective is to build on our preliminary investigations into data heterogeneity, drawing on the noise-injection experiments previously conducted on synthetic datasets. We will also assess the efficacy of using a shared synthetic dataset on the central server as a benchmark to evaluate the integrity of incoming model updates and detect potential malicious activity. Finally, we plan to move from the simulated FL environment currently facilitated by the Flower framework to a fully distributed architecture. By deploying distinct nodes to represent separate corporate entities, we will empirically investigate and address the communication bottlenecks inherent in practical FL deployments.
Disclaimer: This content was created with AI assistance. All research and conclusions are the work of the WPP AI Lab team.